主题:AccMPEG: Optimizing Video Encoding for Accurate Video Analytics
报告人:李一宏
简介:文章探讨如何实时压缩视频并将其从边缘端流式传输到远程服务器,同时保留足够的信息以允许服务器端的视频分析神经网络进行推理。文章提出的具体做法是在边缘端部署一个可以预测视频帧中每个宏块的编码质量的神经网络,边缘端根据预测结果实时调整视频的编码质量。文章为这个边缘端神经网络提出了一个叫accuracy gradient的学习目标,它可以反映宏块的编码质量对服务器端视频分析神经网络准确性的影响有多大。
这篇文章的idea比较简单,就是在边缘端部署一个可以预测需要传输的视频的一个帧的encoding quality的模型,边缘端根据模型预测结果实时调整视频的encoding quality,用一个帧的encoding quality预测结果应用到一个chunk上。
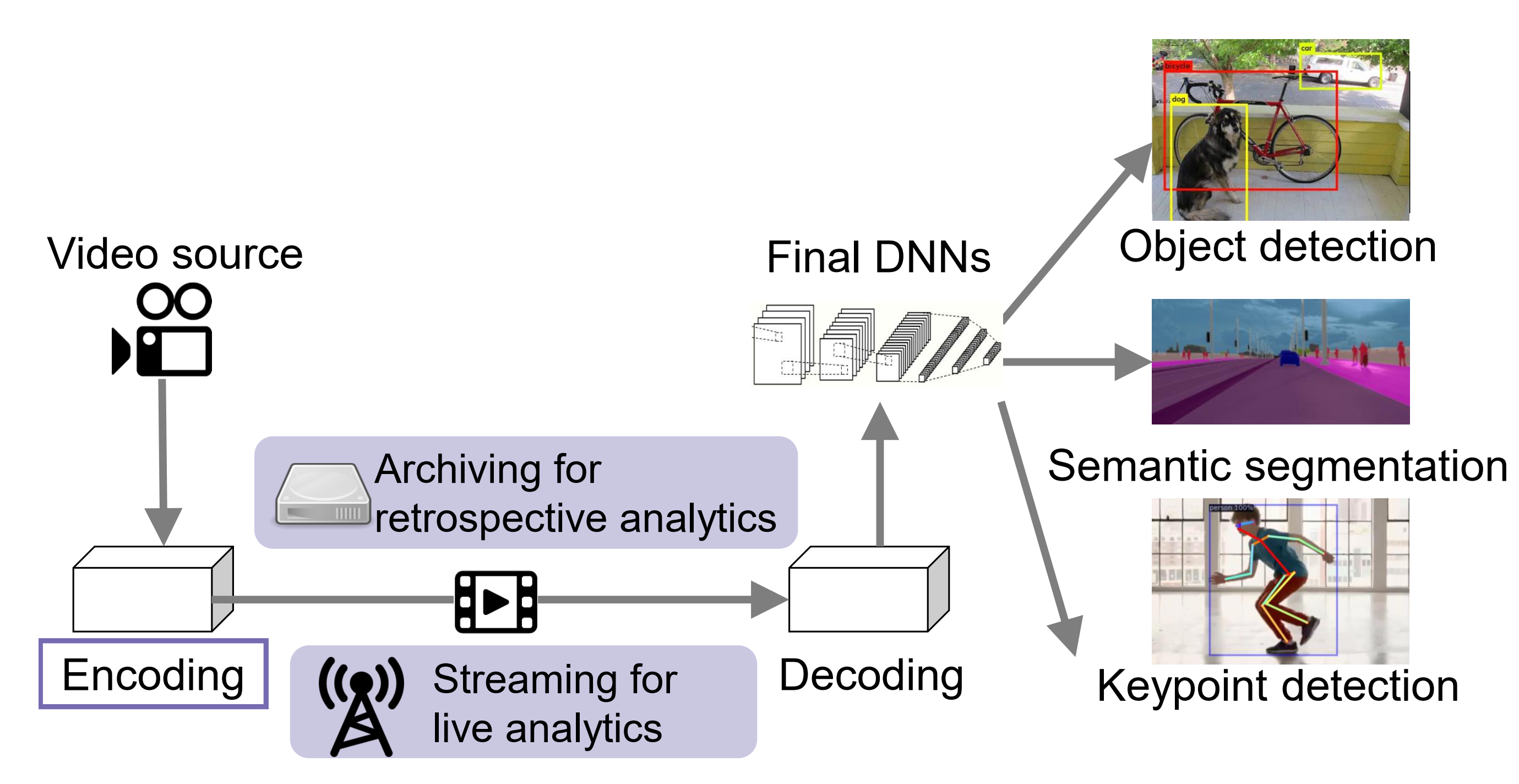
video analytics的过程,需要保证High accuracy,Low delay和Low camera cost。
简单算一下大小,假设720P的视频,12807203*30/1024/1024=79.1015625。
有些论文还会将服务器的推理结果返回给client,这篇论文就没有考虑这种情况。
Limitations of previous work
edge端的frame filter,如果视频内容不是静止的,或者视频分析任务要求分析每一帧的话就不合适
edge端的object-based encoding,用一些heuristic或者object detector去区分背景和物体的编码质量,文章认为一是heuristic不够准确,二是精准的object detector需要更多边缘计算资源。我对目前的高精度object detector在边缘端部署不是很了解,如果可以做到的话在边缘端决定编码质量是要更好的。
server端的region proposals回传给edge端用来指导encoding,这分为两种情况,server端能不能基于最新的帧给出region proposals,如果能看到帧,会有延迟,虽然也有提出一些机制可以去应对这种情况,比如两周前其他同学分享的mobicom19的文章,它就是利用编码技术里面的Motion vectors去预测bounding box会移动的方向。
模型不同部分边云分开部署,对中间结果(feature maps)进行压缩。它在小任务上可能表现得好,但在复杂的vision tasks这其实并不比直接传视频好,比如有些大模型的一个帧的feature maps的浮点数可能比它原始的RGB的值都要多。
Accuracy Gradient的定义。B是一个块,i是块里面的一个像素点,H和L是高画质图像和低画质图像,D(x)是video analytics的推理模型,输入图像输出推理结果,Acc函数是计算两个输出推理结果之间的相似度。
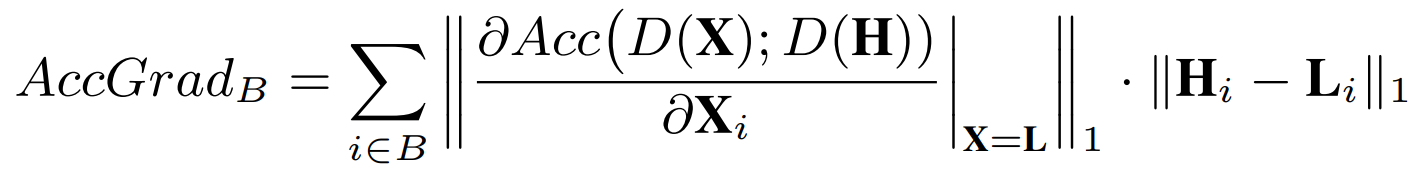
文章在附录里面给了这个定义背后的数学含义,是从最大化Acc出发,通过拉格朗日中值定理转成这个样子,但我觉得它的推导很牵强,意义不是很大,就不展开讲了。我在这里讲讲我的理解,后一项H和L的L1距离,比如说对一片蓝天的压缩,不会怎么影响RGB,低画质和高画质的RGB可能是接近的,所以这个值越小,提升画质就越没必要;前一项是一个梯度,把Acc函数的定义域是L到H,那如果全程的梯度都很大,说明从L到H对准确率的提升很明显,前一项越大说明对推理结果影响越大。但是文章用的是在L这个位置的梯度,就是说我只通过L点的梯度去估计我全程的梯度,这是没有什么理论保证的,因为L到H的Acc函数的形态是未知的,它甚至都不一定单调。
如果用这样的指标去指导编码会有什么好处呢,和object-based encoding比较,在方法上的优势:

AccMPEG的流程,quality selector由服务器训练,部署在边缘,它和普通的object detector相比更加轻量,因为它只输出16X16个Marcoblock的Accuracy Gradient,它的计算量也是很小的,例如和语义分割相比,因为视频编码一般分成16X16的块,它相当于一个16X16的二分类语义分割。有点像神经网络分析可解释性的saliency maps,不过saliency maps是反映像素值对结果的影响,accuracy gradient反映的是一个块的编码质量对结果的影响。
Accuracy Gradient超过一定的阈值,就会将它和它周围的k个块提升到高的quality。文章里找的k的值是5。
编码以一个chunk为单位,一个chunk里面10个帧的编码都按前面的quality assignment来编码。
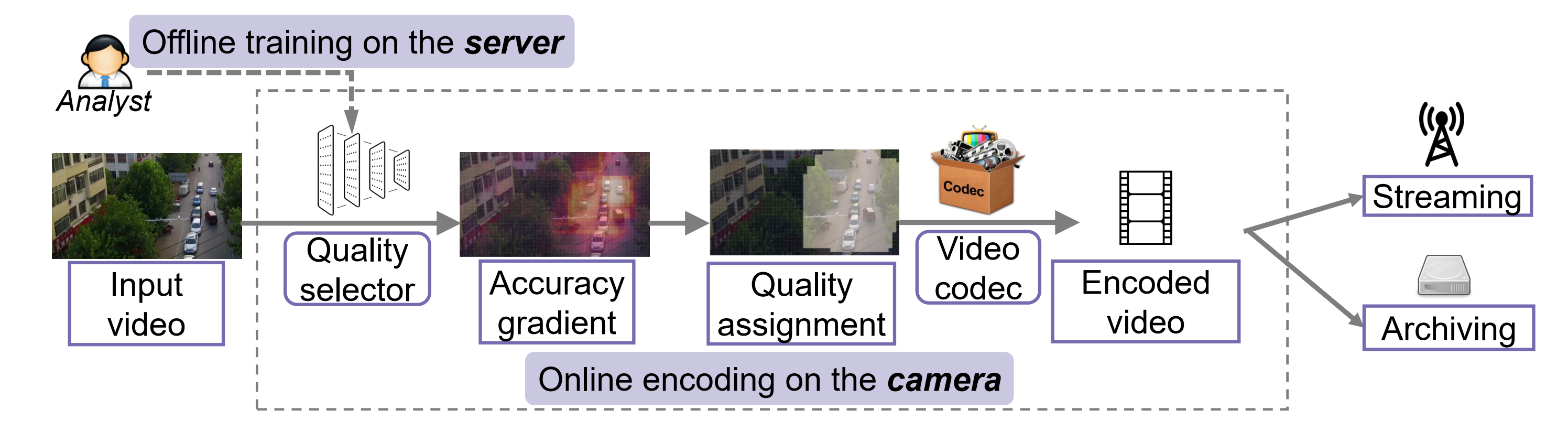
文章通过QP(Quantization Parameter) 控制每帧视频中每一个宏块的压缩量。实际上,QP 反映了空间细节压缩情况。QP 越大,细节信息丢失的越多,码率也会随之降低,但图像失真也会越严重。也就是说,QP 和码率成反比。
在 H.264/H.265 的视频编解码里面中,QP 的取值范围为 [0,51]。文章是只选其中两个值,来作为低画质和高画质。
除了调QP还可以调ABR和CRF,ABR是已知一个固定的目标码率,动态调整视频质量,让编码器来计算如何才能达到我们设定的目标码率。CRF(Constant Rate Factor)CRF 是 x264 和 x265 编码器的默认质量/码率控制设置。CRF 的取值范围为 [0,51],数值越低,质量越好,文件越大。
实验
AccMPEG的模型在一个数据集上训练,就可以在不同的DNN之间迁移。
作者在实验里让EAAR直接获得新的region proposal,而不是根据前一帧来预测region proposal,这是相当于假设EAAR有最优的tracking,是稍微对文章自己有点不公平的比较。
限制
如果视频内容和训练内容不一样,性能就会下降;
而且对于移动很快的物体和小物体上的表现很差。
讨论
mobicom19的文章也有做dynamic encoding,有什么核心差别?一个是本文用了神经网络,二是本文考虑了视频的传输,而mobicom19这篇文章是逐帧传输和推理,甚至还把分成帧分成slice。逐帧传输和推理确实会有更高的准确率上限,这会给带宽带来很大压力。
The bandwidths measured with iperf3 are 82.8Mbps and 276Mbps correspondingly.
实验数据很漂亮,如果现实一旦达不到这个带宽,时延就会变得很大。
极端地来说,不考虑硬件的话,有这样的带宽我都可以直接4K60FPS推流拉流了,为什么还费这个事搞边云协同呢?
而这不代表今天讲的这篇就很实际,用平均0.5Mbps的带宽,100ms延迟的网络环境比较,这个就太有限了,说明大家写文章都会通过在实验设置里面想办法突出自己的优势。
mobicom这篇的问题主要出在,它的设计是逐帧传输和推理的,没有利用视频的时间冗余,虽然帧和帧的处理做成了pipelining,但数据量和视频编码的传输相比是多了很多的,不过对于AR、VR场景,能不能把多个帧打包成一个chunk,我不太了解。
除文章外,还想和大家探讨一下一个系统分析系统的普遍workflow是怎样的,有没有一个现实的、普遍的video analytics的范式呢?我不知道范式是什么,但我觉得它应该要满足几点,
- 传视频chunk到server端,逐帧传输,根据query按需传输(zero streaming或者说in response to retrospective queries:除非视频本身有很多冗余,而且你的带宽是按需付费的场景),过一个filter过滤掉一些没有用的帧之后再传输(如果视频内容不是静止的,或者视频分析任务要求分析每一帧的话就不合适)都是不够普遍的。
- 对视频质量进行部分压缩,可以选择edge端的heuristic filter(启发式的过滤器),一些在线算法,edge端的神经网络预测,以及server端的region proposals发送到edge端(这又分为server端能不能看到最新的帧,如果能看到就是和这篇文章同一个作者的另一篇文章server-driven什么的,如果不能看到就是通过预测的方法,就像mobicom的tracking方法),这些所有方案是精度、edge端算力和时延的three-way tradeoff。从前面的evaluation可以看到其中一些方案性能是咬得很死的,你比我快一点,我比你准一点的差别,video analytics已经是红海了。
- server端负责跑video analytics模型,edge端并不适合所有的video analytics模型。
应该适当跳出这个video analytics这个问题,找一些新的结合点,比如说新的边缘设备,AR/VR,甚至元宇宙这种概念这种我觉得可能会有更多机会。