作者提出的是一个RL和Constraint Programming结合的求解组合优化问题的模型,在RL环境和约束规划模型中引入了基于动态规划模型的编码,编码后学习部分用强化学习进行,求解部分用约束规划进行。简单来说是用RL来辅助约束规划在搜索解空间时的分支决策。
为什么可以用动态规划呢?强化学习应用于组合优化问题是model-base的,既知道状态转移的情况,也知道reward函数。但是我觉得不是deterministic transition的情况下也是可以的,因为现在有很多model free的模型(AC)。
论文正文中给的例子是用RL的结果辅助分支界定法,RL的结果作为新的分支,分支界定法是会舍弃掉不可行解的,所以处理了约束问题。附录中还提到RL与另外两种搜索策略的结合。
框架:
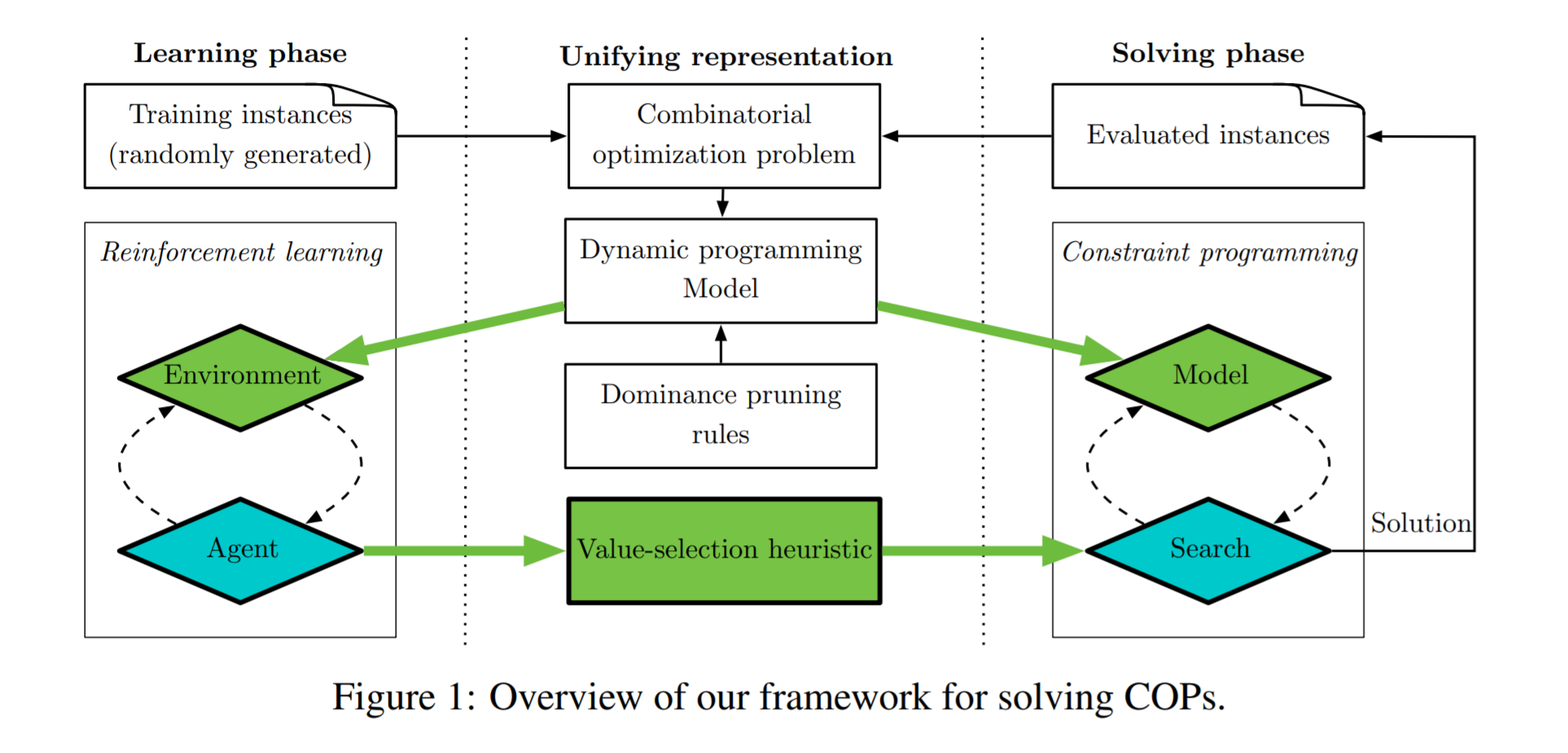
DQN辅助分支界定法:

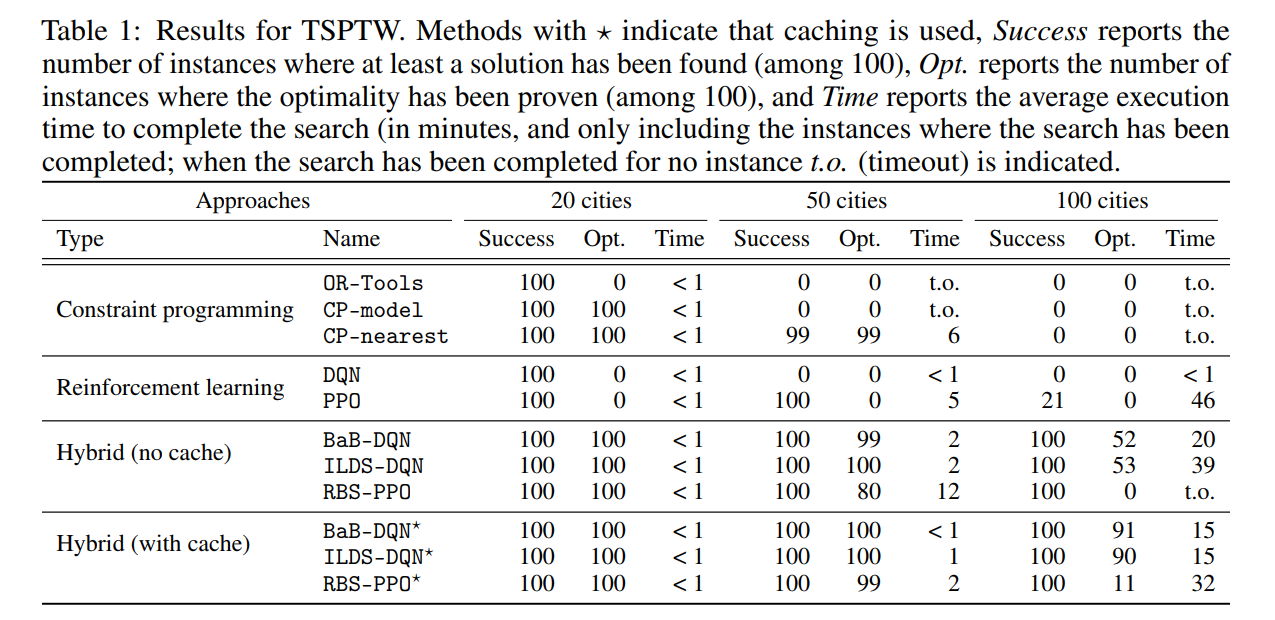
对于有时间窗口约束的旅行商问题,这篇文章是用GAT去编码。最后实验结果比单纯的DRL或者CP要好,与DRL做组合优化的其他文章相比也更好,而且与现行的工业组合优化求解器相比也有优势。
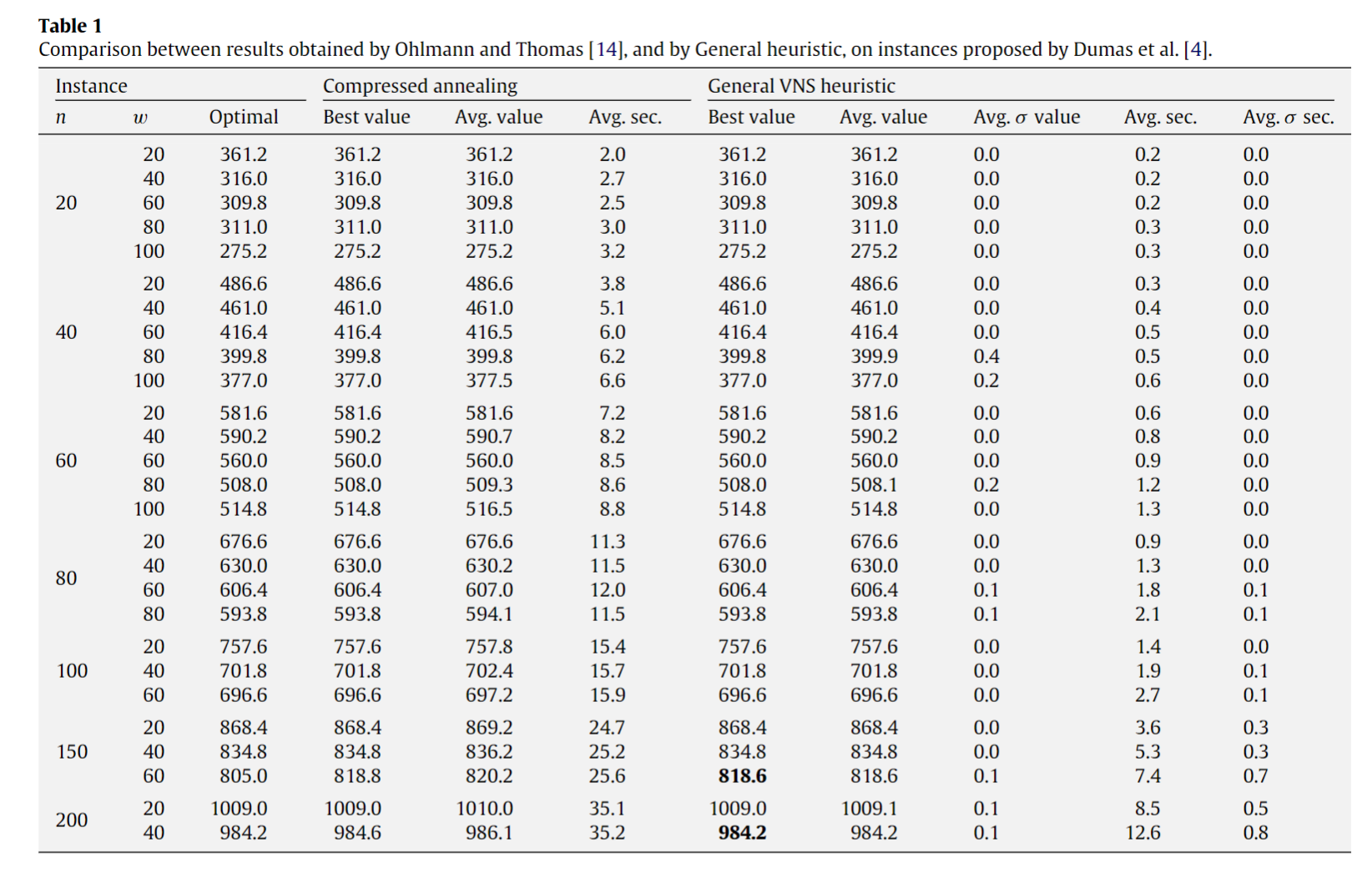
有时间窗口约束的旅行商问题的SOTA heuristic是A General VNS heuristic for the traveling salesman problem with time windows,前人已经用可变邻域搜索(VNS)的方法解决得很好了,能不能强化学习+VNS?
代码写得挺好的,RL和CP的主要结合点在这里,分支定界法取分支的时候,由DQN给出一系列Q值,CP选择最大的那个Q值对应的action,把domain分成采取这个action和采取其他action。

基于这种方法,有人还做了一个叫SeaPearl的CP求解器框架,用强化学习作为value-selection heuristics,用图作为输入。