为了实现多机架的负载均衡cache,提出两个idea。
一是多层的cache,每一层用不同的hash函数,即不同的划分方式。
二是Power of Two Random Choices的路由方法。Power of Two Random Choices的大白话解释是假如顺序地将请求发送到n个服务器,策略是从n个服务器中随机独立均匀地选择两个,然后选择服务器负载最少的处理请求。这样的算法以非常高的概率,n个服务器中最大负载为(1+o(1)) loglogn / log2 + O(1)个请求。
原始的Power of Two Random Choices和本文不同的地方在于,原始的是随机地找两个服务器,本文是hash到两个指定服务器。
多机架的负载均衡cache,可以很容易想到两种方法,Cache partition和Cache replication,前者是将不同的cache划分在不同的node上面,但这没有解决负载不均衡问题;后者将所有cache都放到不同的cache node上,这有一致性的开销和存储的开销。
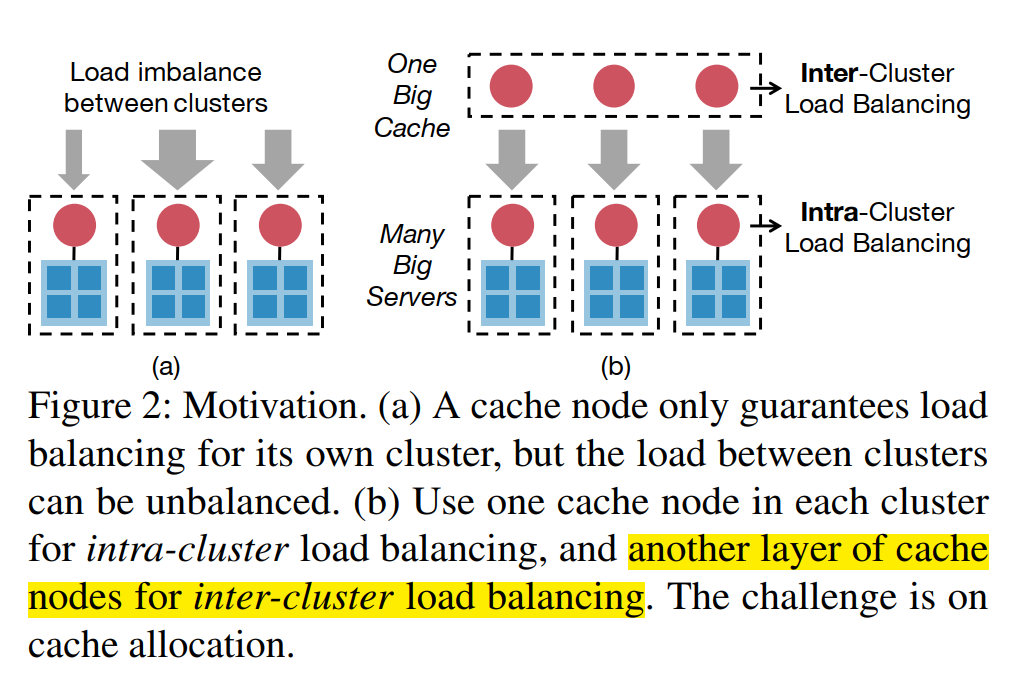
下面层的cache node只负责cache自己服务器上的hot items,上面层用了不一样的hash function,相当于将下面层每个cache node的item都分散开来。然后对一个key上下两层会各有一个cache node,这时选负载最低的cache node响应请求。
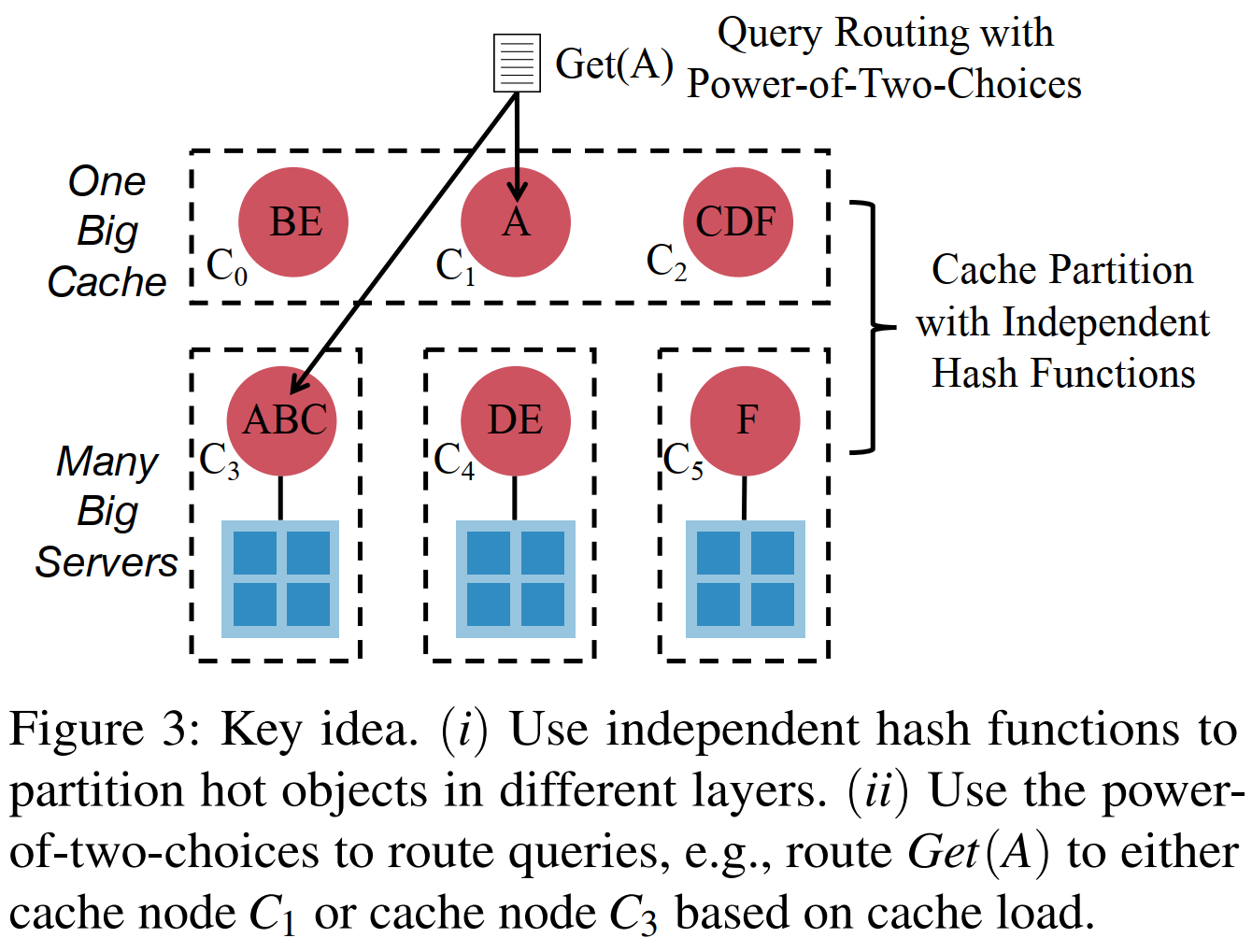
文章把问题看成一个找完美匹配的问题,用了一些图论,排队论的知识去证明这个power of two choices可以实现,无论请求的分布如何,总的吞吐量都接近全部机器的最大吞吐量总和(也就是实现负载均衡)。其中一些截图没有解释的变量:m是cluster数量,p_i是i对象的请求概率,R是总的响应量,波浪T是一个cluster的最大吞吐量,P是所有的p_i。

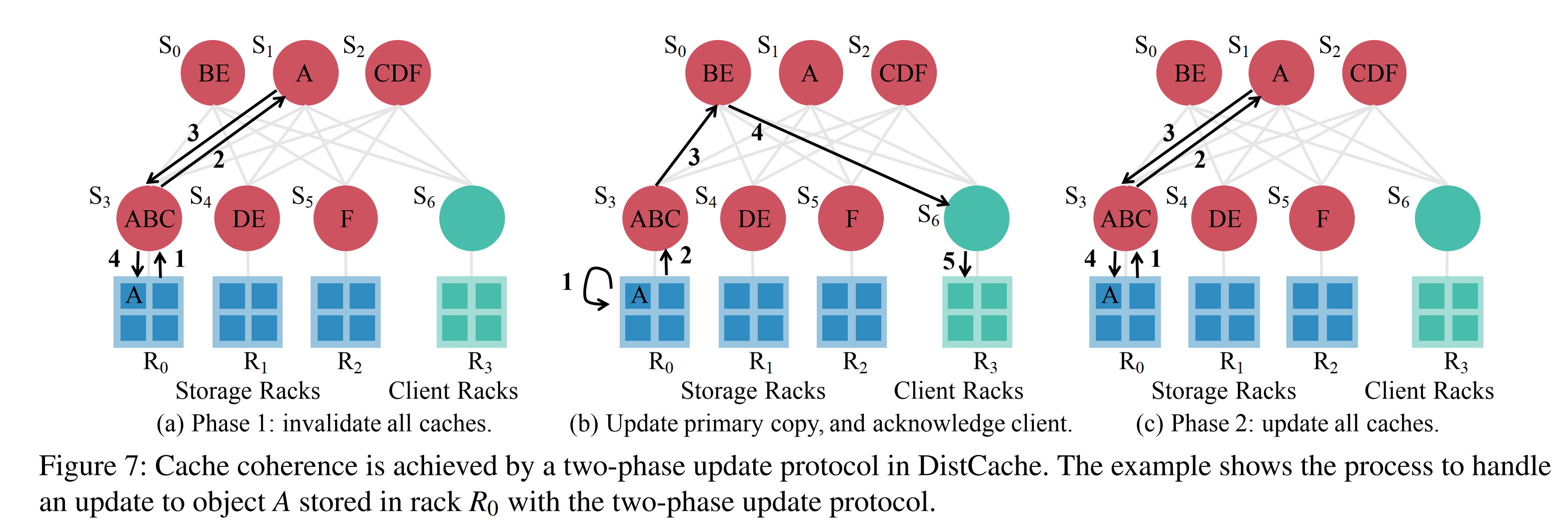
其他的内容就和NetCache差不多,不同的主要在缓存一致性上面。怎么同时原子更新不同cache node上的缓存?文章的解决方法是two-phase update protocol,收到写请求时先无效化所有缓存,storage server让一个无效化的数据包传遍所有cache node最后回到storage server。最后传一个数据包更新cache。
cache的更新则用的是NetCache的HH detector的监测方法,但有些不同在于本文用一种不需要controller的方法。Specifically, the agent first inserts the new object into the cache, but marks it as invalid. Then the agent notifies the server; the server updates the cached object in the data plane using phase 2 of cache coherence, and serializes this operation with other write queries.
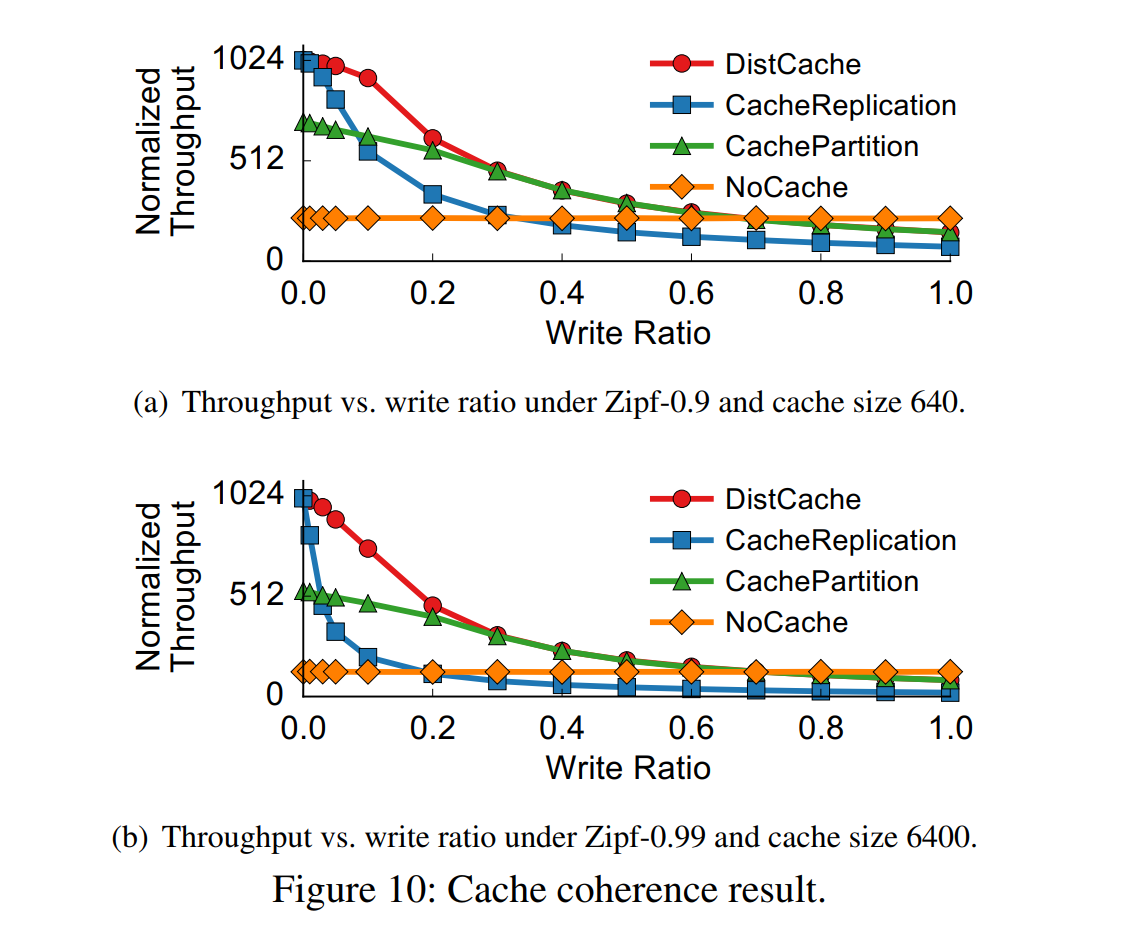
DistCache的性能表现,似乎不太明显。