用了很多分布式系统的思想。
在线更新推荐推理系统,优化了P2P的通信,而且考虑了模型更新的优先级和差模型对SLO的影响。
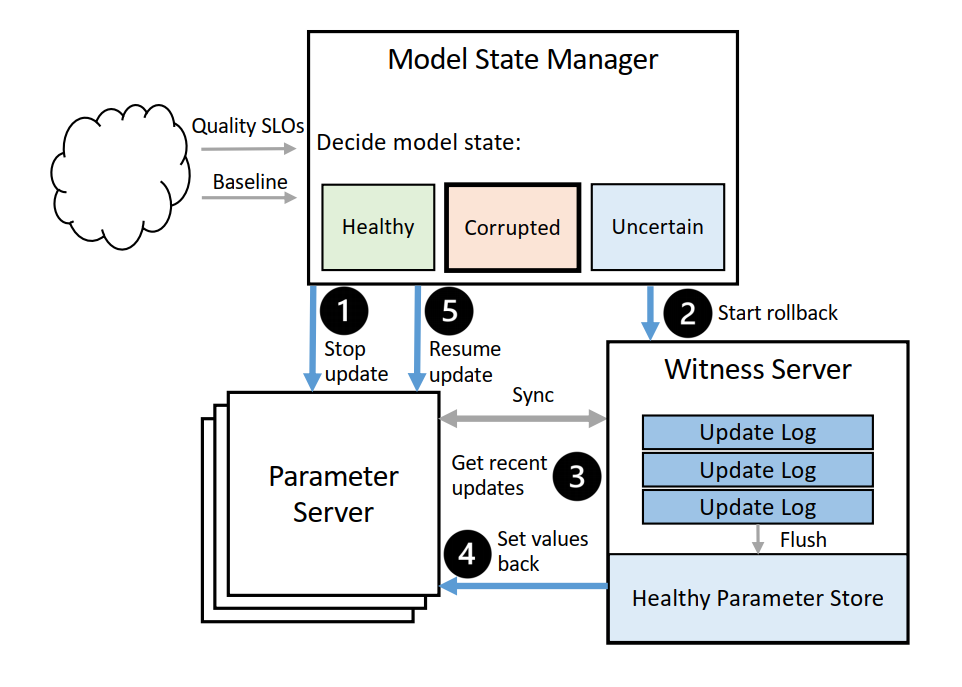
差模型的影响通过一个 inference model state manager 监控,它有一个几分钟前的baseline模型,它会接收部分的用户流量作为ground truth去评估现在的模型。
对模型的parameter分片传输,达到最终一致性,作者认为一个模型的不同参数版本不一致,对推理结果影响不大,只要最终一致就可以;用version vectors去做replica之间的P2P同步,物理时间+id作为一个parameter的version number。
用一个Dominator Version Vector去维护cache,保证大于Dominator Version Vector的版本都在cache里面,删除过期cache会更新Dominator Version Vector的计数 (merge)。

如果Version Vector比Dominator Version Vector大说明所有东西都在缓存中。
Shard Version是和replica绑定的,Shard Version少很多,是为了减少Version Vector做的二级数据结构;Shard Version大,Version Vector肯定大。

update priorities考虑的因素是freshness,gradient magnitude和request rates的多项式。
为每一个模型准备一个baseline模型,是几分钟前的模型参数,用于监控模型更新有没有变坏。
witness servers用于记录update,但是不会即时flush也没有update priorities,当infernece server需要rollback的时候才flush。