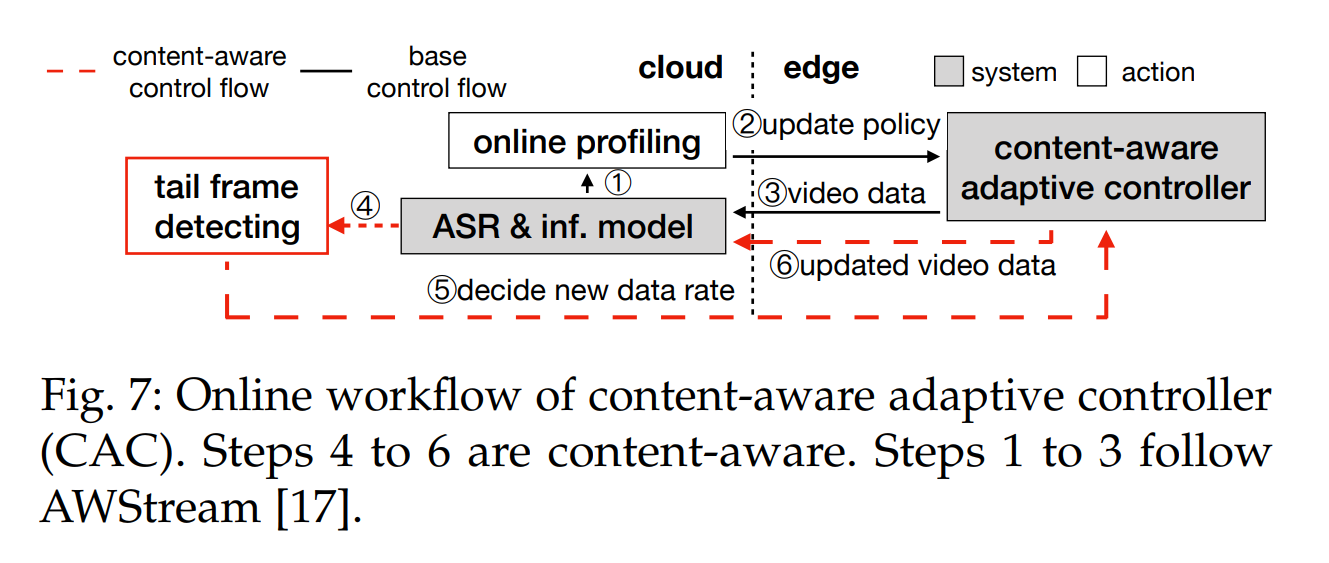
Kai Chen老师组和Xin Jin老师的工作,中了infocom21,然后扩刊TCC22。
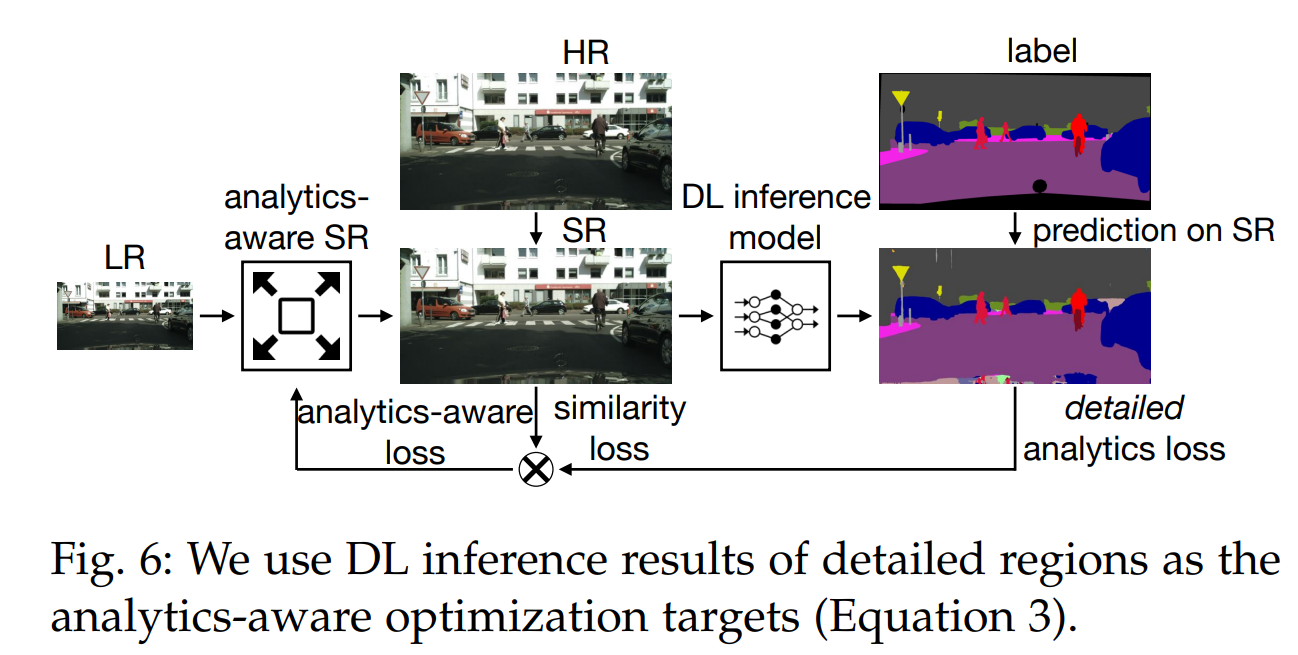
感觉超分辨率比较适用于改善人眼观看的视频质量,不太适用于改善video analytics,很容易导致超分辨率重建的单帧比原来还模糊。
在训练超分辨率模型的时候把video analytics的模型接上,多算一个loss,这个loss还需要是特挑的small regions类的目标(比如只选单车之类的小物体,天空建筑这种就不选),但如果video analytics有多个或者一直在变怎么办?对这个领域不是很了解,感觉idea有点太简单了吧。

关于怎么确定frame-wise tail也很简单,就是看small regions占的比例有没有1%,如果没有就会产生很多误判,就属于tail frame,然而在实验结果中作用并不大。