这篇文章认为in-network aggregation对减少训练时间的提升很有限,它的作用应该在于减少在一个共享ML集群中的网络带宽的使用。
文章refer了另一篇文章An In-Network Architecture for Accelerating Shared-Memory Multiprocessor Collectives的分析,in-network aggregation对ring allreduce的理论最大提升只有2倍,考虑ring allreduce分为scatter-reduce和Allgather两个阶段,每个都需要传输和接收一次和设备数量n成比例的信息,in-network aggregation可以看成一个超快的parameter server,可以做到需要一个阶段,所以理想是2倍,现实往往还没有2倍。文章构造了很多communication bound的场景去说明,即使通信被优化,实际加速效果也没有那么好。
为了解决可编程交换机的浮点数限制,作者将可编程与交换机解耦,设计了一个新的支持浮点数运算的加速器硬件。这样看好像智能网卡一类的硬件的应用要更general一点,不一定要交换机。
为了更好地共享网络带宽,提出了一些在共享ML集群中用可编程交换机需要解决的问题(负载均衡和拥塞控制)的方案。
考虑fat tree的拓扑结构,文章提出的框架假设使用什么节点是其他算法给定的,而且不假设是否所有任务都使用in-network aggregation,流量超过某个大小的流才用ING。
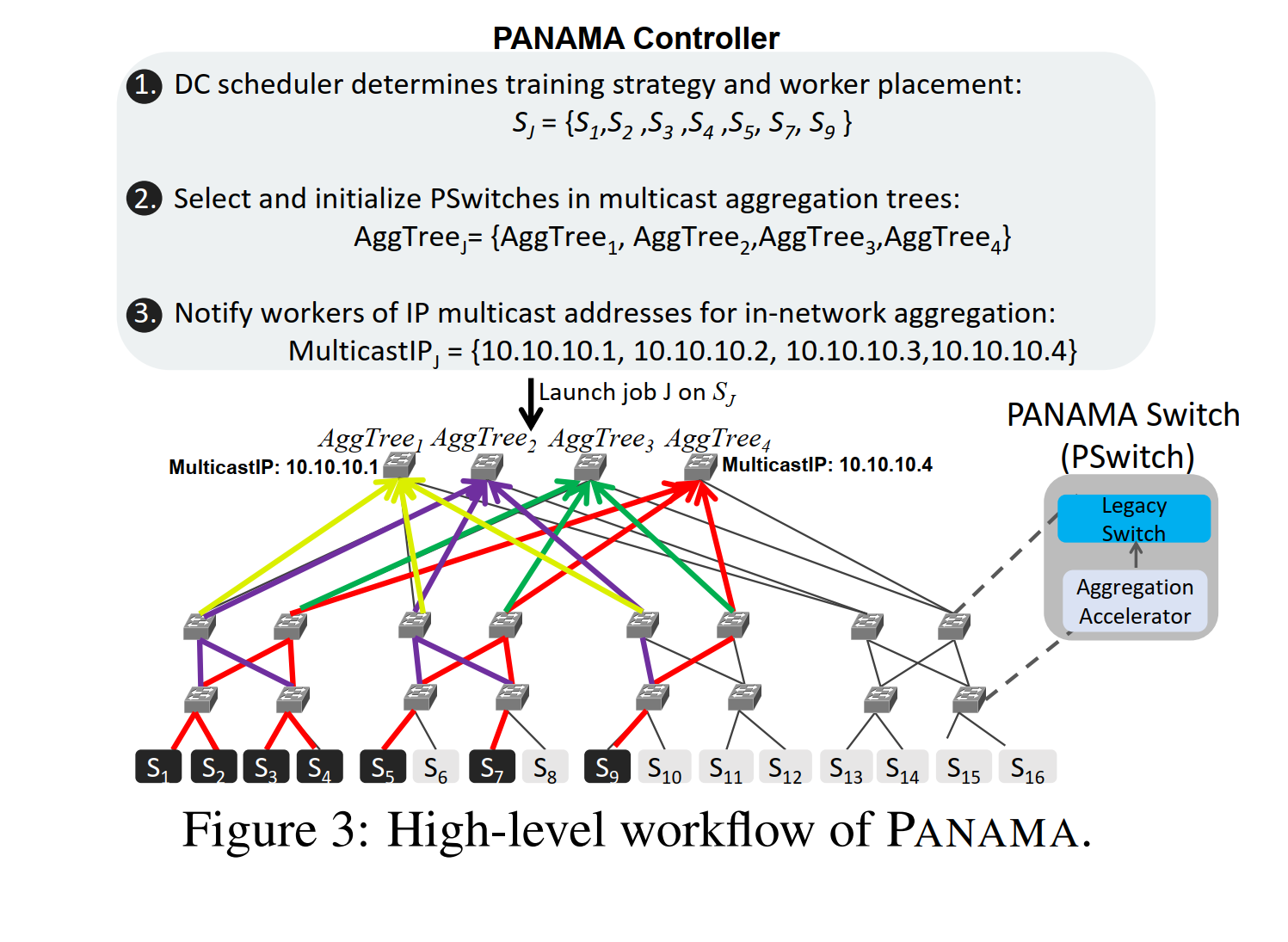
文章提出的load balencing方法就是对每个任务规定多棵聚集树,每棵树负责相同大小的gadient块(round robin分配),树内用标号大小来区分顺序。
对于拥塞控制,文章是在TCP的ECN拥塞控制上面做了一些算法上的适配,我的理解是它的算法在逐层聚合梯度的时候,顺便将ECN位聚合起来,如果ECN不为0,则整颗聚集树一起降低传输速率,同时会有一个由加速器硬件指定的可用buffer空间,防止溢出,总体来说都是简单的heuristic。

作者用FPGA实现了它设计的加速器硬件,因为对FPGA不是很了解,这部分看不懂的名词特别多(只看懂个lookup-table和flip-flop),感觉之后做FPGA的可能性不大,有需要再看。PS: 想看有没有开源代码看看整个FPGA项目是怎么实现的,发现只有两个空的代码仓库。https://github.com/nadeengebara