Embedding placement problem is essentially the same thing as cache optimization problem, and many of the ideas are similar.
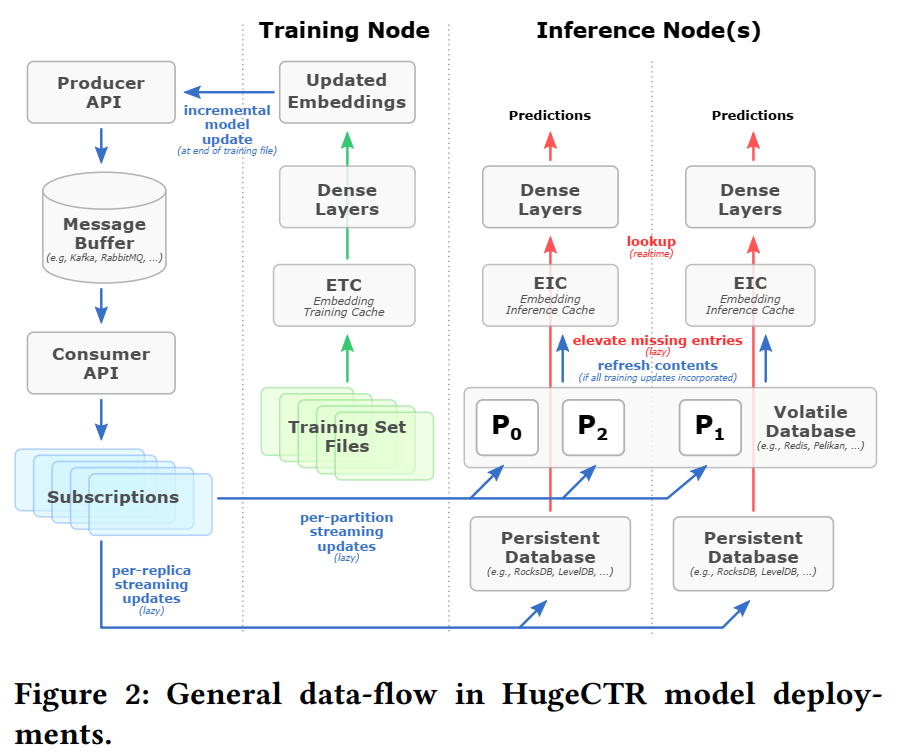
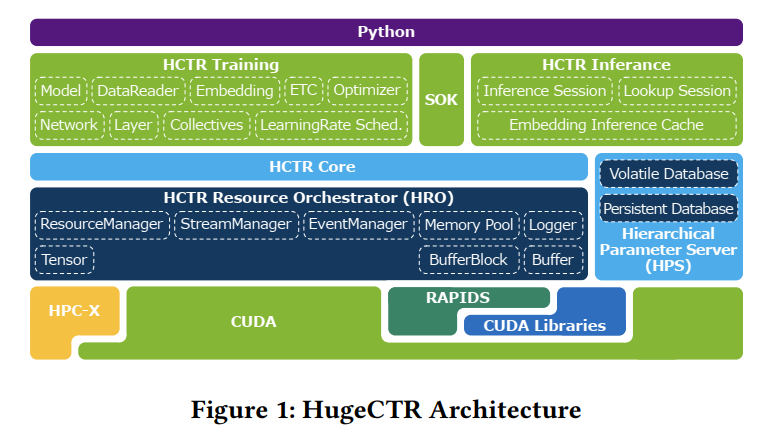
Merlin HugeCTR combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks.
Since late 2021, Merlin HugeCTR additionally features a hierarchical parameter server (HPS) and supports deployment via the NVIDIA Triton server framework, to leverage the computational capabilities of GPUs for high-speed recommendation model inference.
Hybrid sparse embedding is a key technique for achieving industry leading performance in large-scale recommendation model training with NVIDIA GPUs. It combines DP and MP for maximum performance. When doing forward or backward propagation, a local cache is used to speedup access for high frequency embeddings and avoid the need for communication between GPUs (DP). For low frequency embeddings, HugeCTR allows utilizing memory across all available GPUs to realize load-balanced sharded embedding feature storage (MP). The all-to-all communication pattern is used to exchange embedding vectors between GPUs.
It is quite different from our idea. We combine DP and MP in a different way and the framework requires no all-to-all communication.
It enables doing inference for models with huge embedding tables. HPS is implemented as a 3-level hierarchical cache architecture that utilizes GPU GDDR and/or high-bandwidth memory (HBM), distributed CPU memory and local SSD storage resources.