idea是用可编程交换机去做服务器in-memory KV的缓存。KV的workload是偏差很大的,容易造成负载不均衡,和其他方法相比,可编程交换机比内存快几个数量级,而且数据移动,一致性等要比在存储节点上做replication更好。
文章提出的不是一个高命中率的cache,它主要作用是load balancing,命中率只有不到50%,只保存O(NlogN)的个item。文章假设服务器是per-core sharding,缓存一致性不用考虑NUMA架构,只是写直通。也不考虑是否需要鉴权,就只考虑负载均衡cache这一件事。
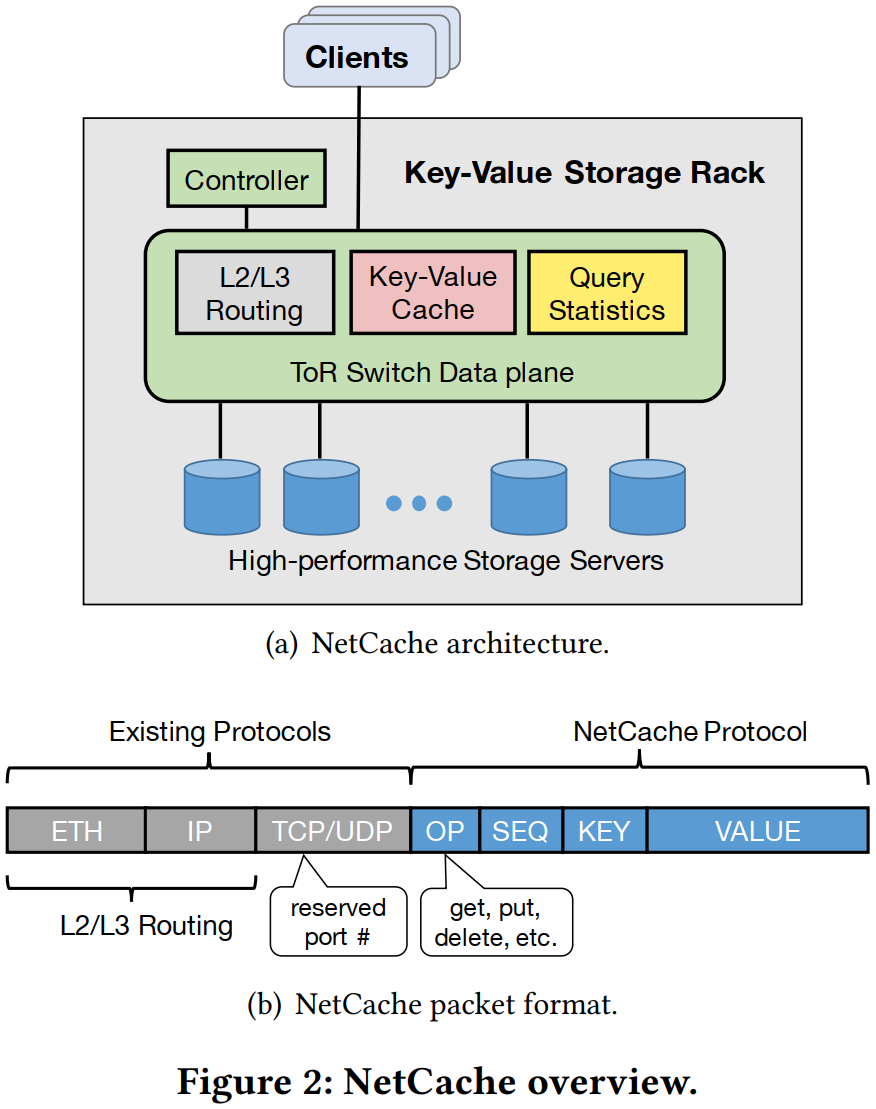
整体架构如下,NetCache协议在L4数据包里面。
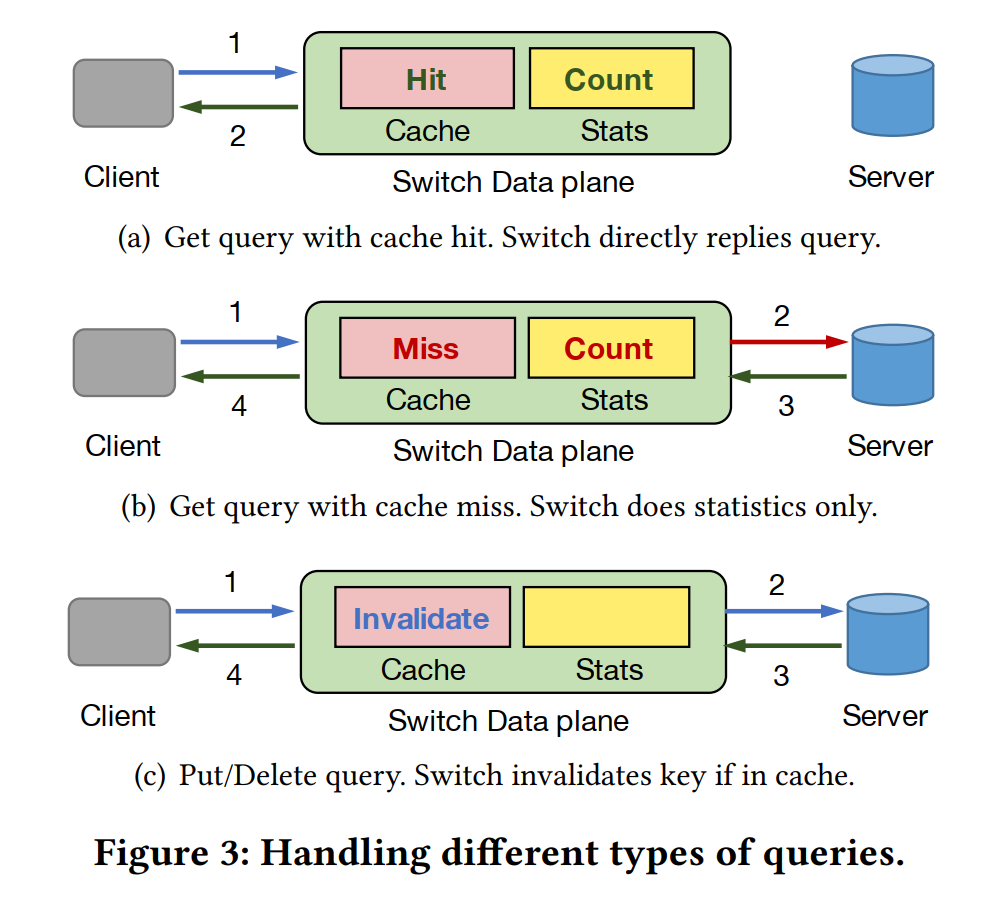
处理请求的流程。

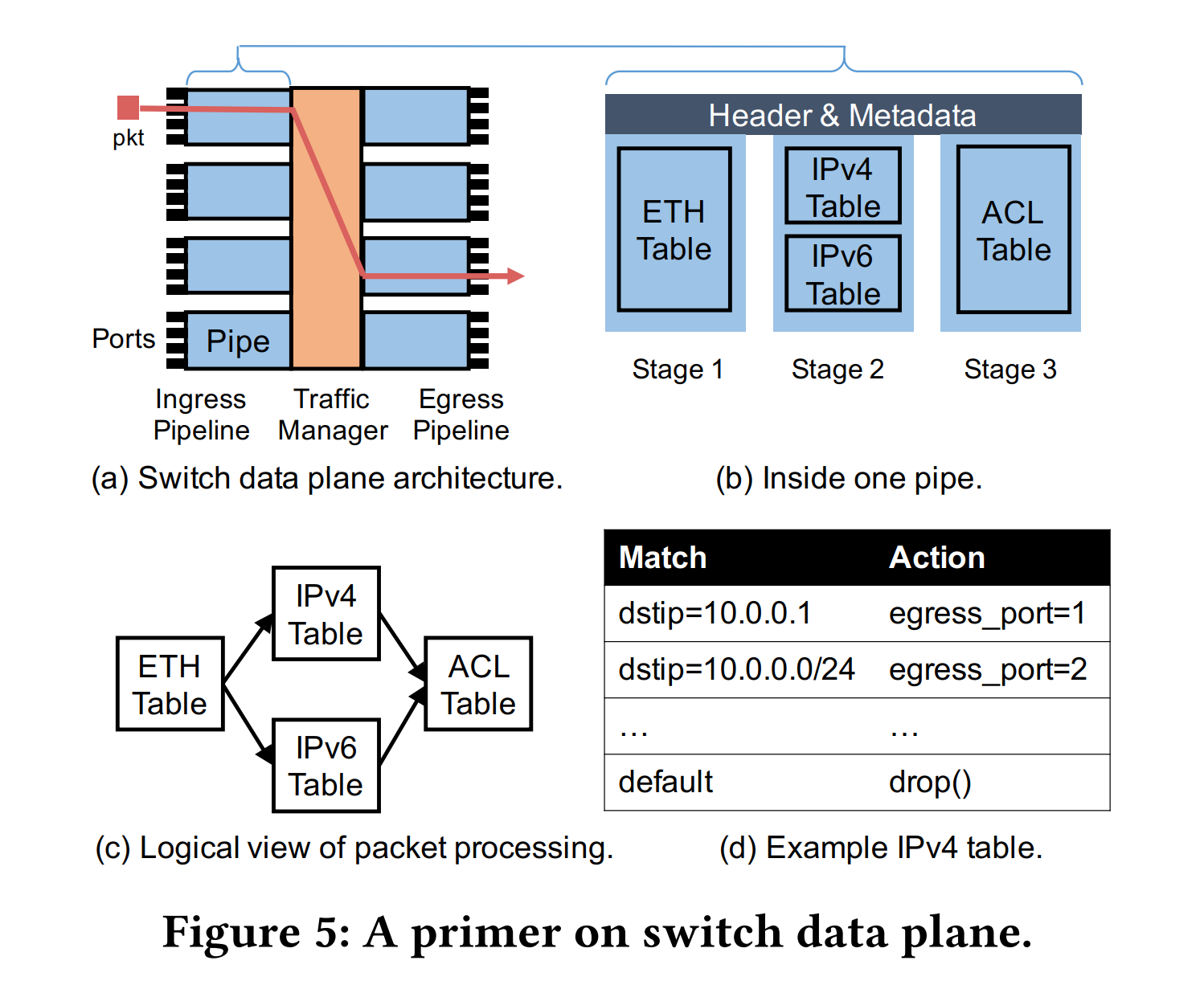
可编程交换机的数据面是一个pipeline,每个pipe有多个ingress/egress ports和中间不同的stage,每个stage有自己的计算资源,stage之间也可以共享数据。数据包的处理可以抽象成match-action table,每个table检查header的字段,根据match的结果执行一些action。
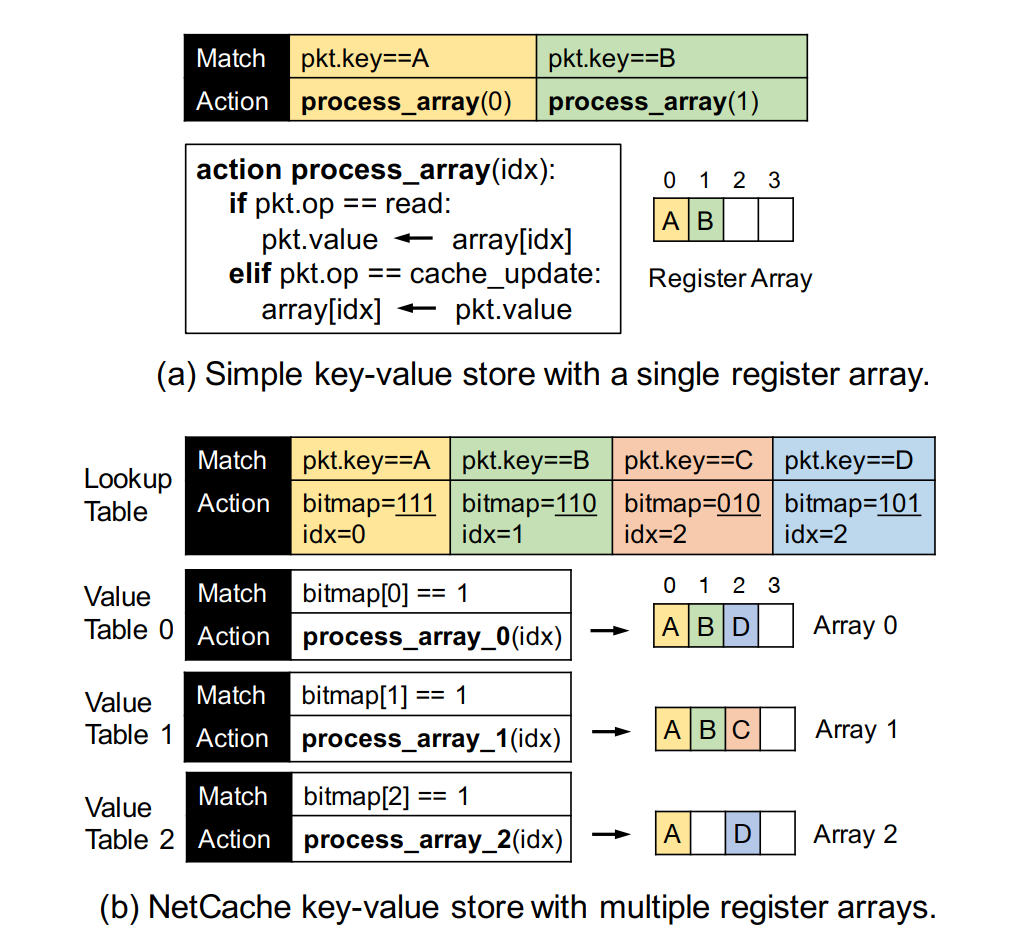
通过可编程交换机保存cache的方式如下,首先一个lookup table保存所有的item元信息,通过bitmap来记录哪个stage的table上有数据,以及数据在什么index上。通过switch data plane更新值带来一个限制,它不能比旧值的数据更长,这是因为其他stage的同一个index可能已经放了别的数据。
而怎么选择cache应该放在哪里,可以看成背包问题,文章用的是first-fit,外加周期性的memory reorganization(这部分没有明说)。

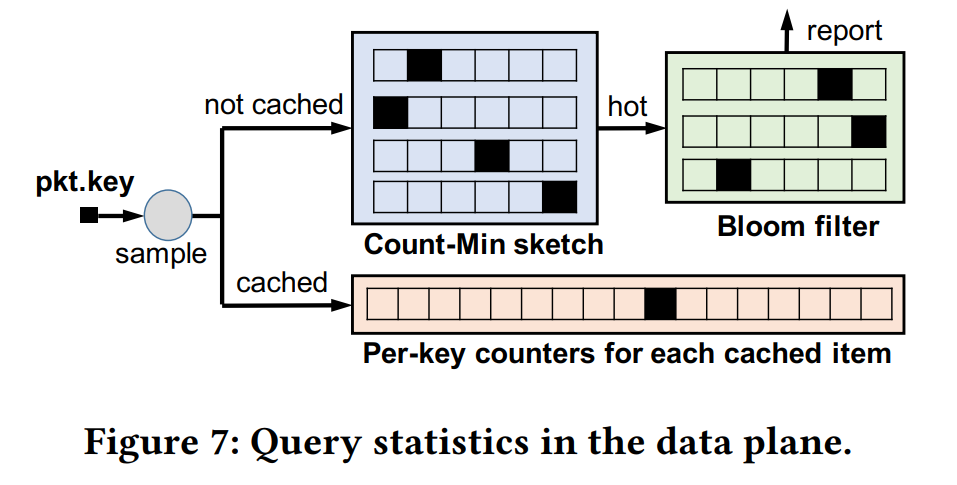
有一个对每个key的counter和heavy-hitter detector的机制去决定缓存什么item,每次更新cache时,sample一些key的counter,与未cache的访问最多的key的访问次数比较,从而决定要不要更新。对于未cache的key,用的是Count-Min Sketch算法。而后面的bloom filter的作用应该是过滤掉已经report的key,在cache成功后应该会把它对应的位复原。
stage的放置也是有讲究的,lookup table要放在ingress pipe,每个pipe上都要有备份,这样可以处理所有ingress端口的请求;cache value要放在egress pipe,可以把属于不同server的内容放在它所对应的egress端口所在的pipe上。

这个系统也还是有一定缺陷:
- 目前是单机架的;
- key和value目前是限长的;
- 对写入占多数的workload不友好。