这个工作也是可编程交换机上实现KV store,但相比于之前的NetCache的优点是可以直接在可编程交换机的数据面上写数据,并用多个交换机实现chain replication去做备份,并且带有整套完备的routing, handling out-of-order delivery, failure recovery的机制。
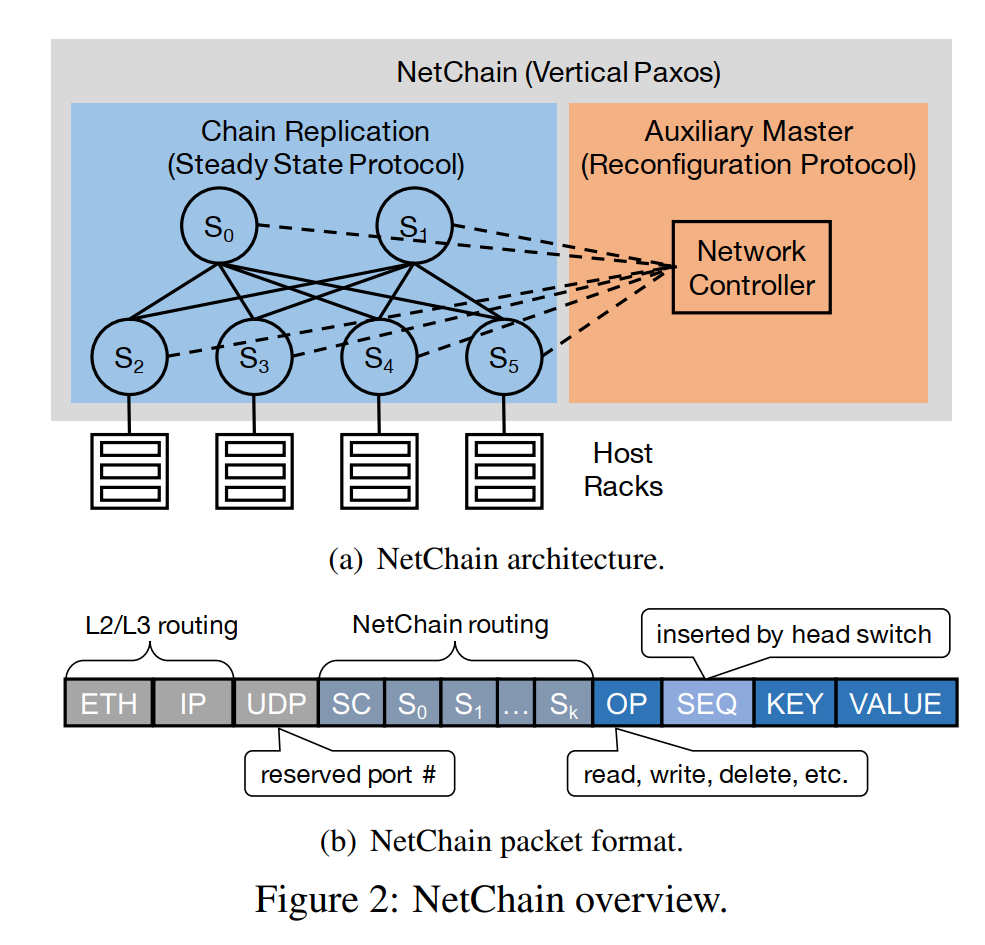
文中提到采用了Vertical Paxos去备份数据,其实也就是chain replication,Vertical Paxos的本质是它将数据备份的协议和控制的master分离,可以change the configuration of acceptors within individual consensus instances,是一个普遍的共识算法类型,并不特指某种算法,chain replication是Vertical Paxos的一种实现。
there is only one consensus protocol, and that’s Paxos
系统支持在数据面直接Read和Write,但是Insert和Delete需要控制面的操作,也就需要更多时间,由client对key进行一致性哈希,选择(f+1)个virtual nodes组成的chain,就可以决定在哪条chain上存取。所以chain replication是对于virtual node来说的,一个switch在 (f+1)*virtual node数目 条chain上。发生reconfiguration的时候需要client,server和switch同时调整,但reconfiguration只在fail的时候触发,所以可以接受。
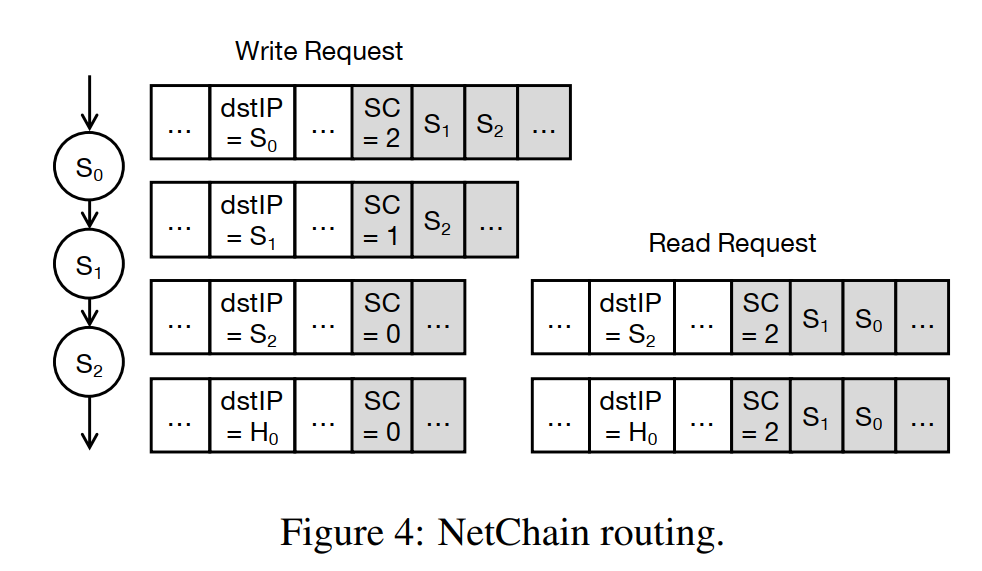
路由直接用已有的underlay的协议(也就是IP层路由),不用真的连接成一条chain。
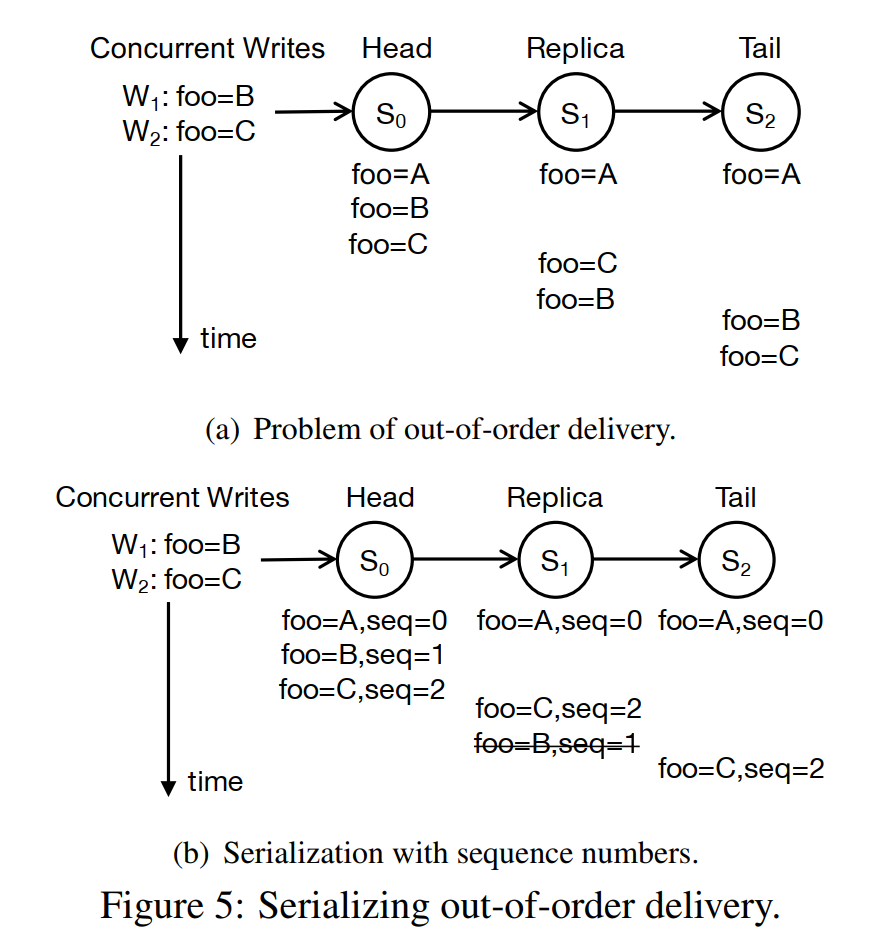
保证一致性的方法是通过seq number实现的,这样如果一个事务要写入多个值,就会导致脏写,但这个也很好保证,就是在写入的时候block其他写入,但这样系统的吞吐就不会那么好看。文章后面也提到NetChain does not support multi-key transactions,并argue说如果一定要实现的话可以把多个value pack起来,但这明显并不是general的方法。虽然最终的值是一致的,但不同节点的log可能是不一致的。
因为考虑了多个备份chains,而且是带虚拟节点的一致性哈希,所以当一个switch fail之后要重配置很多个switch。文章考虑只重配置neighbor switches(它不一定是保存数据的可编程交换机),在neighbor switches上加规则绕开failed switch,然而因为virtual nodes+一致性哈希,所有的switch都是neighbor switch。
在恢复时把fail switch对应的virtual nodes分配给不同的live switches,也可以全部分配给一个新的switch。对于中间节点和头节点的恢复,过程大概是先预复制后一个节点当前的状态,此时不停止写入;然后停止写入,完全复制后一个节点当前的状态,再将新switch入链。
对于头节点的恢复,因为头节点是确定写请求seq number的,所以为了保证严格大于fail node的seq num(极端情况是新的头节点恢复后还有数据包飘在头节点和第二节点的路径上,而新的头节点复制第二节点的状态里没有这些数据包,导致seq num不一致),将seq num设计为 (session number, sequence number),在换头节点的时候session number加一。
而对于尾节点的恢复,尾节点要复制前一个节点的状态,但在第二阶段的完全复制时需要drop掉neighbor switch的所有写入和读取请求,但这样此时新的尾节点和前面n个节点是不一致的,而可编程交换机又不支持回滚,不会导致之后读取到写入未成功返回的值吗(比如在client retry之前新的尾节点再fail一次,然后系统让前一个节点接受读取请求,但前一个节点有未commit的数据),我不理解。除非在client端保证,在写入操作没有成功返回之前,不能任何其他client访问这个key,否则感觉这个方法在机制上有硬伤,作者又没有讲清楚。