OSDI: Elastic Resource Sharing for Distributed Deep Learning虽然说是elastic,但是在分析的时候是只考虑任务本身资源伸缩的开销,而没有考虑context switch的开销。
active-standby用内存空间换switching overhead。
不同的context之间:
Multi-Instance GPU(并行)只有NVIDIA H100, A100, and A30支持;
time slicing(并发)则从Pascal架构开始支持,而且提出MPS之后,将多个进程的CUDA Context,合并到一个CUDA Context 中,流处理器就可以被不同的kernel函数共享,可以做到和CPU的多进程并发的效果,但他们需要所有的数据都preload到显存中。
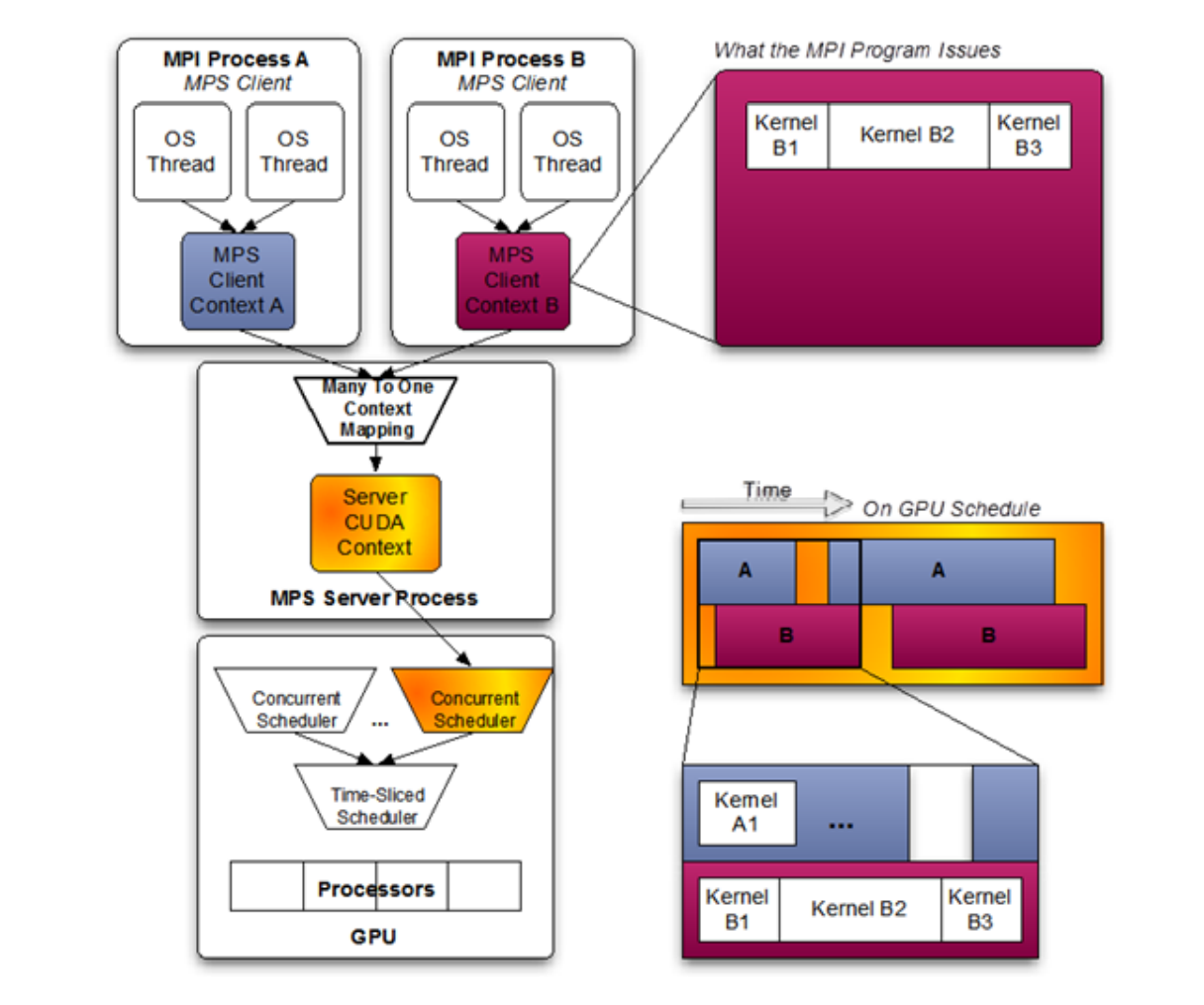
多个stream里面的kernel的并行是一直支持的。
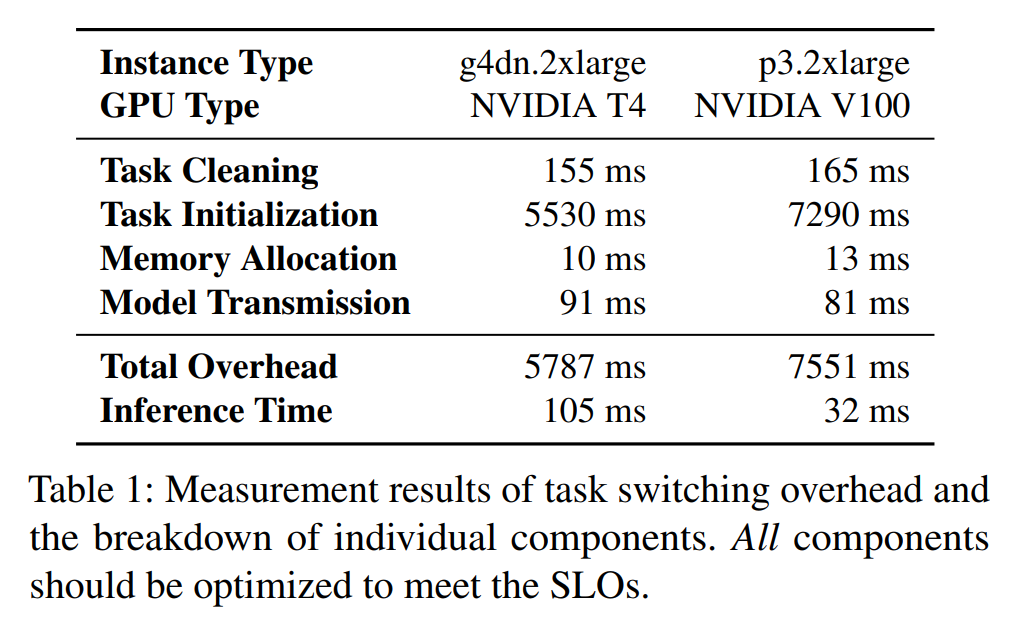
switching overhead由四个部分组成:
old task cleaning, new task initialization, GPU memory allocation, and model transmission via PCIe from CPU to GPU.
observation: DNN models have a layered structure and a layer-by-layer computation pattern
文章的idea就是模型一层层地传,然后边传变算。
the core idea is pipelining model transmission over the PCIe and model computation in the GPU
divide layers into groups, and design an optimal model-aware grouping algorithm to find the best grouping strategy for a given model
parallelizes old task cleaning in the active worker and new task initialization in the standby worker
PyTorch CUDA runtime loading通过worker复用解决。
深度学习编译做完一些fusion之后的推理模型的layer怎么在读取模型的时候做grouping和hook。
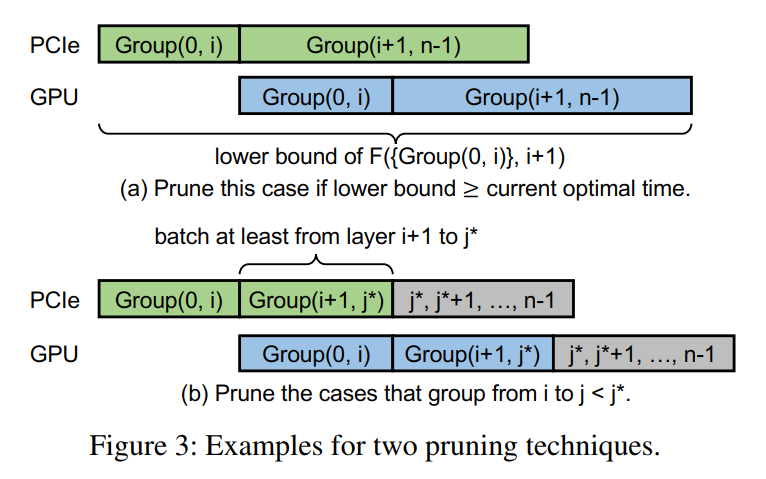
深搜回溯加分支定界,有两个地方可以剪枝。
一个是当前的下界已经超过当前找到的最优解时,就可以忽略。
一个是传输时间少于前一个group的计算时间的可以忽略。
用一个统一的内存管理守护进程去分配GPU内存,然后把内存指针分享给worker进程。
给我的工作的启发是,如果要做GPU的share,首先要设计好task packing的方法,保证显存可以装下,不会发生swap;如果实在不能保证不发生swap,就要自行设计内存管理,做好对这个特定应用的内存swap优化,可以是pipeline也可以是其他方法。