前言
Ray主要是想做一个集成分布式训练、推理和环境模拟于一身,但是彼此又不耦合的分布式框架。经过合理的模块化,每个环节还可以接入不同的系统,例如为训练接入Horovod/torch.distributed,为推理服务在Kubernetes上运行Ray等,让用户可以在一个分布式应用上组合多个库。
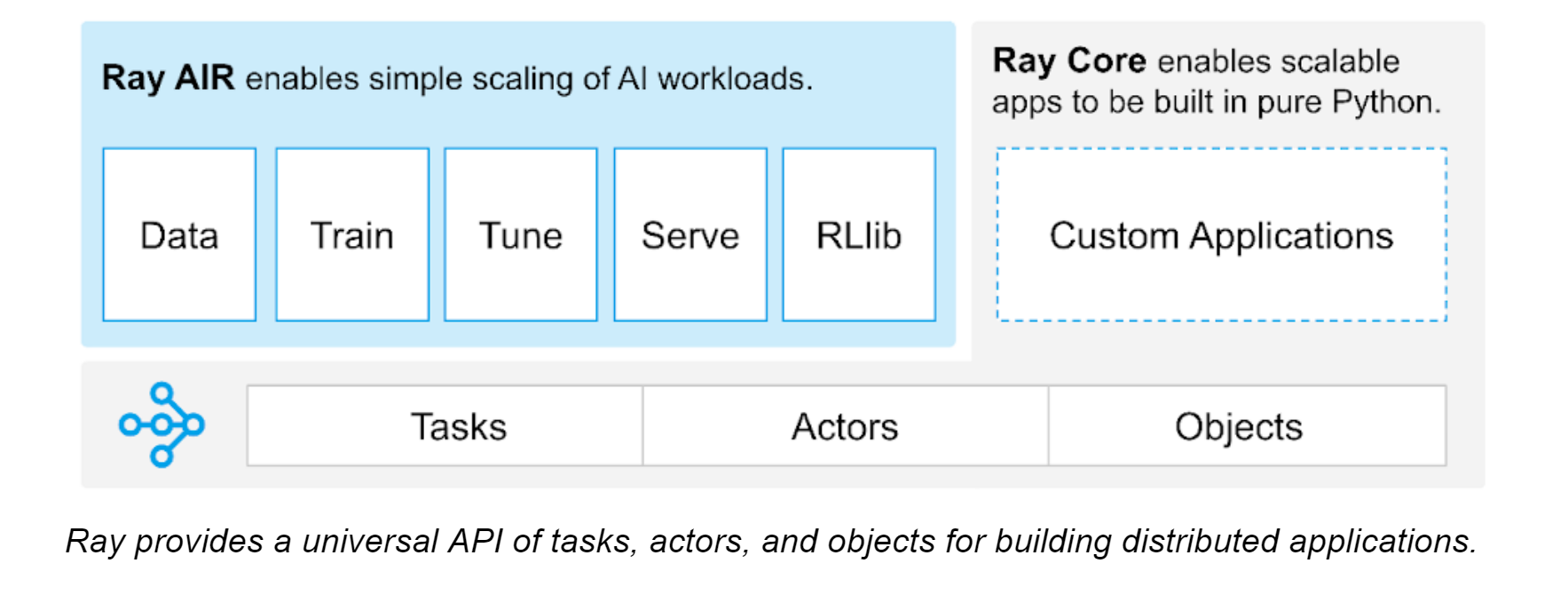
Ray更关注的是horizontal scalability和low overhead,当然scalability一般还会要求reliability。Ray的存储是个分布式的内存共享机制,通信基于gRPC。
一个简单的Ray使用示例:

Application concepts
- Task - A remote function invocation. This is a single function invocation that executes on a process different from the caller, and potentially on a different machine. A task can be stateless (a
@ray.remotefunction) or stateful (a method of a@ray.remoteclass - see Actor below). A task is executed asynchronously with the caller: the.remote()call immediately returns one or moreObjectRefs(futures) that can be used to retrieve the return value(s). - Object - An application value. These are values that are returned by a task or created through
ray.put. Objects are immutable: they cannot be modified once created. A worker can refer to an object using anObjectRef. - Actor - a stateful worker process (an instance of a
@ray.remoteclass). Actor tasks must be submitted with a handle, or a Python reference to a specific instance of an actor, and can modify the actor’s internal state during execution. - Driver - The program root, or the “main” program. This is the code that runs
ray.init(). - Job The collection of tasks, objects, and actors originating (recursively) from the same driver, and their runtime environment. There is a 1:1 mapping between drivers and jobs.
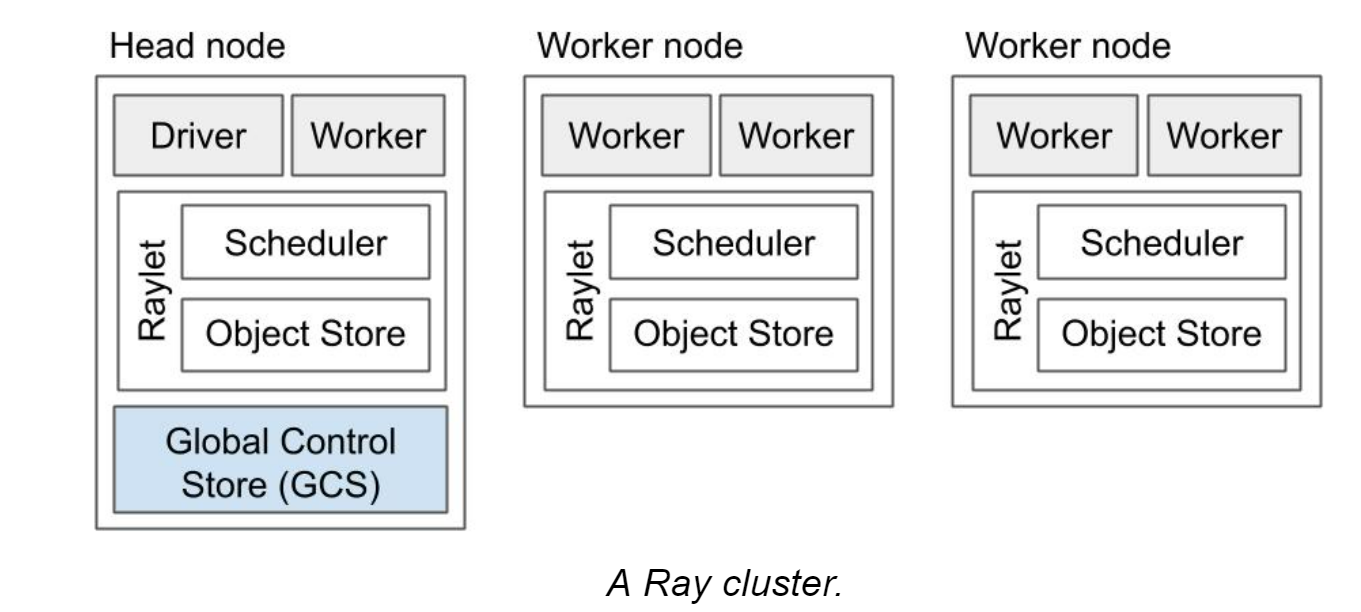
一个全局的信息表在head nodes之间存储并replicated/sharding,每个node有一个Raylet,运行scheduler并保存大object结果或输入,实现控制和计算解耦。所有这样的分布式共享内存都是在内存上,节点本地用LRU决定是否保存到下一级存储。内存的object有counting的机制实现GC。
scheduler
感觉这样的状态机,负载大的时候很容易死循环。
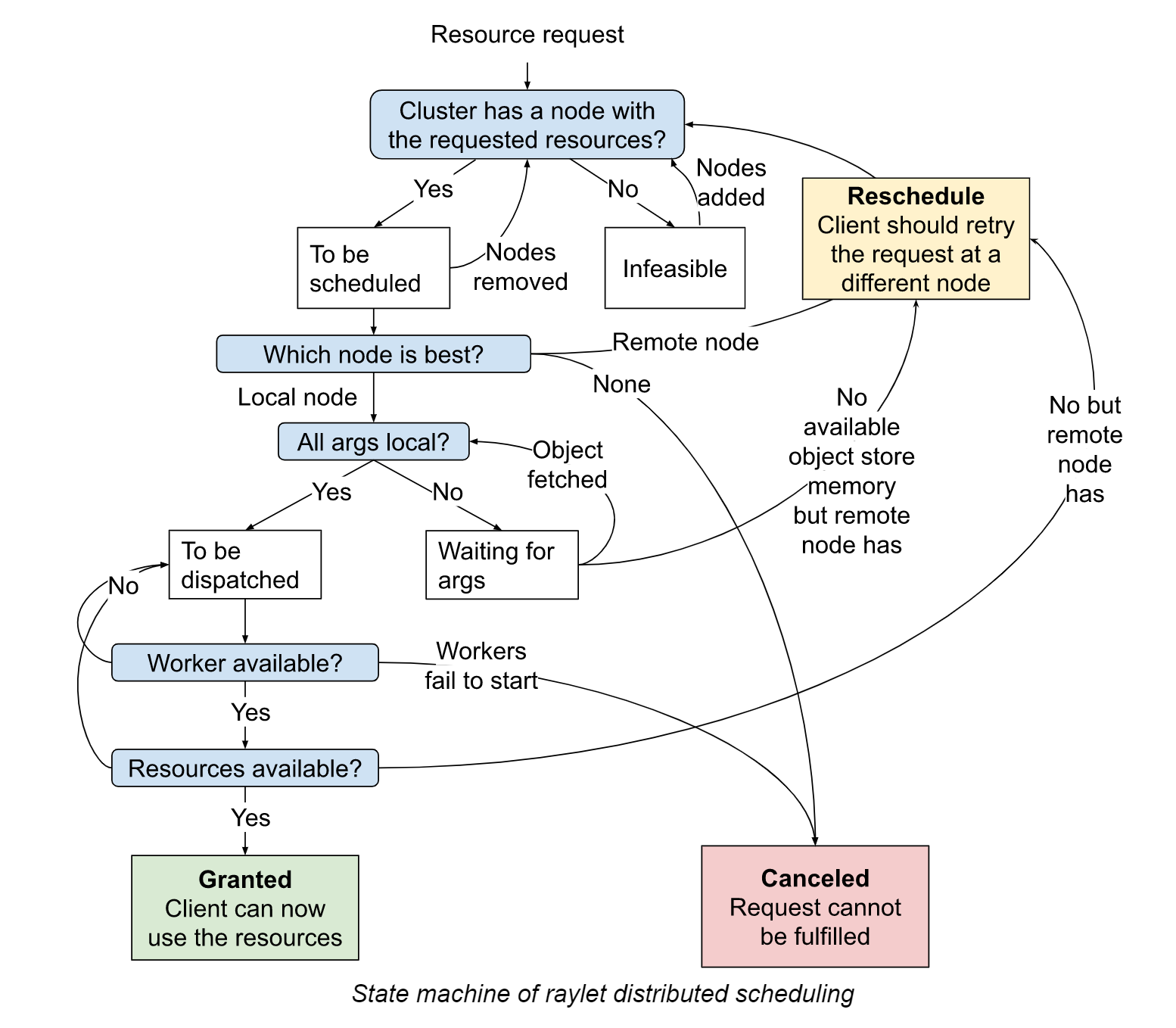
K8S也是这样,按id的顺序去塞任务到节点里,知道节点的load达到阈值,这样可以保证id顺序在后面的机器是空的,给了autoscaling留了优化空间。

与原论文不同,Ray v2用的是分布式调度器,本地调度器在资源不足的时候请求其他节点上的本地调度器,而不是一个global调度器。
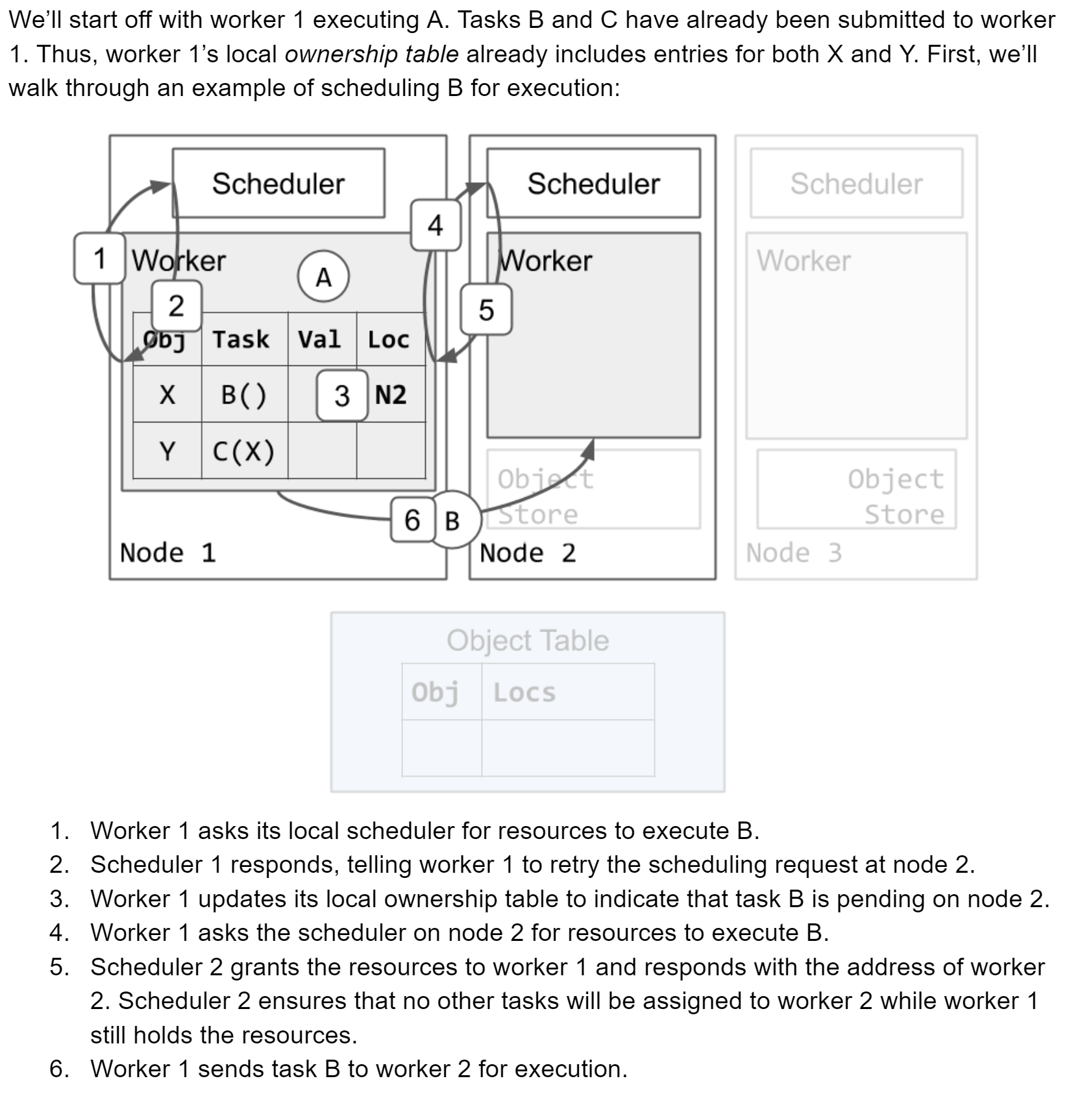
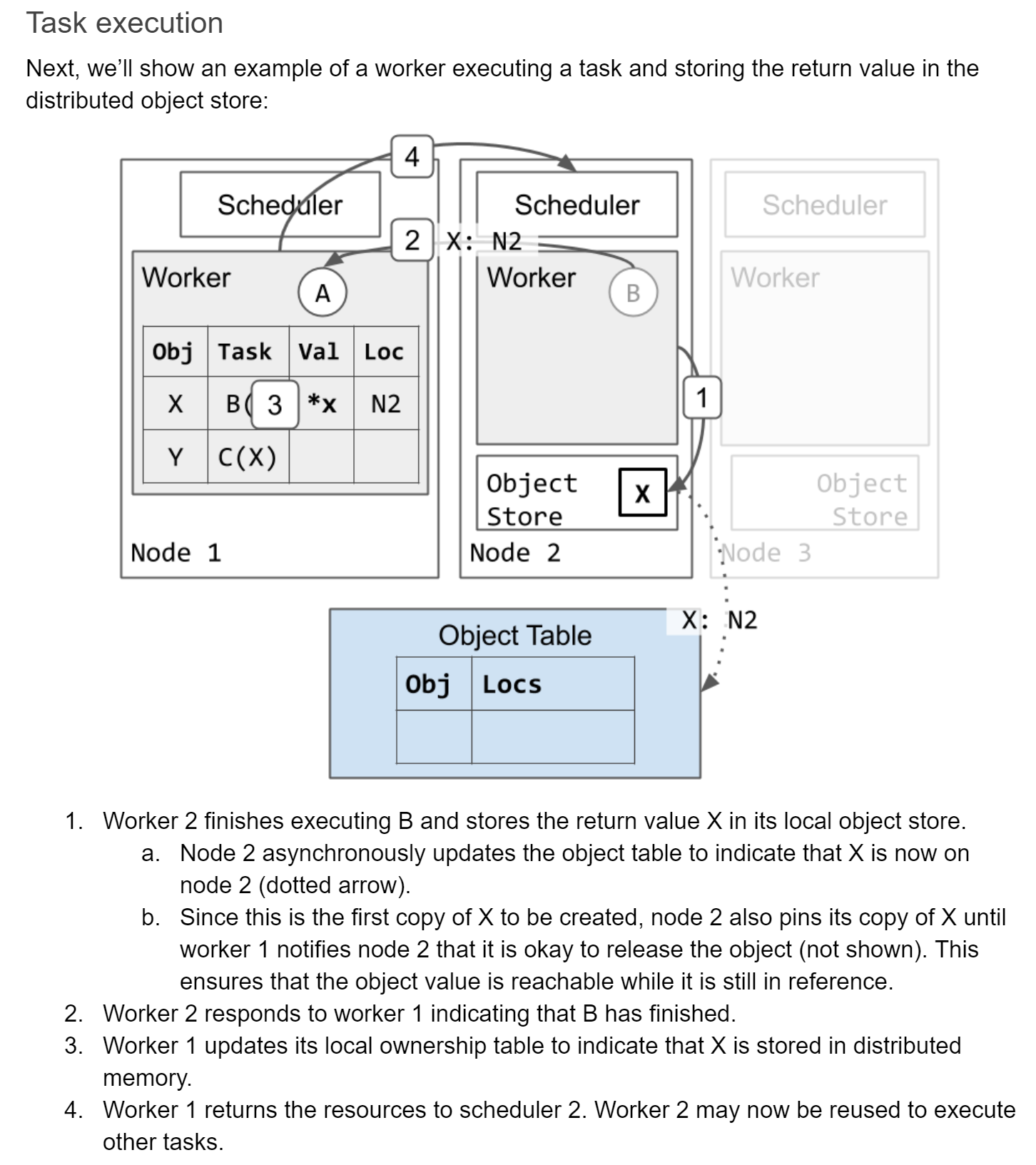
用一个全局的object表(保存在GCS中)记录节点们分布式运行的任务结果,结果对应的节点地址存在表中,需要到节点的本地存储中读取。