作者认为一直传输视频很浪费带宽,实际上只有很小一部分视频会最终被query。而且摄像头的存储成本很低,便宜的摄像头也能存一个月的视频。作者提出zero-streaming,摄像机将视频存在本地,对查询做出响应。查询分成多轮,每轮产生及时有效但不一定准确的中间结果,多轮逐步将结果的准确率提高。
文章的核心idea有两个:
- 文章认为稀疏但非常准确的知识比全面但没那么准确的知识更重要,所以文章的设计是每隔一段时间(例如30s)给一个帧(叫做landmarks)做高精度的目标检测,结果可以用于优化之后的查询。摄像头的算力一般能够支持0.1~0.5 FPS的高精度目标检测。

通过收集到的landmarks可以获得一些信息,例如目标大致会出现在什么位置。文章提到会将这些信息用在摄像头端的filter上,但我觉得这样可能会过于激进,以至于遗漏一些unusual cases。
- 在摄像头端,从低到高地用不同精度的模型去query视频,保证容易检测的结果先检测出来。
作者认为可用带宽和模型精度之间有interplay,因为模型检测不出来时要通过网络传输到云端。低精度模型可以更快找到容易检测的结果,但更慢找到所有结果。模型推理速度要匹配传输的速度,所以低带宽应该搭配高精度模型来减少帧传输,高带宽应该搭配低精度模型来更快得到初步结果。
还有摄像头端模型怎么选择处理的帧以及云端怎么选择更新摄像头端模型的问题。前一个模型的结果会用于当前模型决定处理帧的顺序,但也会兼顾没有被前一个模型处理的帧(赋一个0.5 of 1的顺序分数)。如果上传的帧不够有用了(例如包含object的帧数不够多),云端就更新摄像头端模型。摄像头端模型还需要云端根据上传的帧进行训练和评估。
整体的workflow如下:
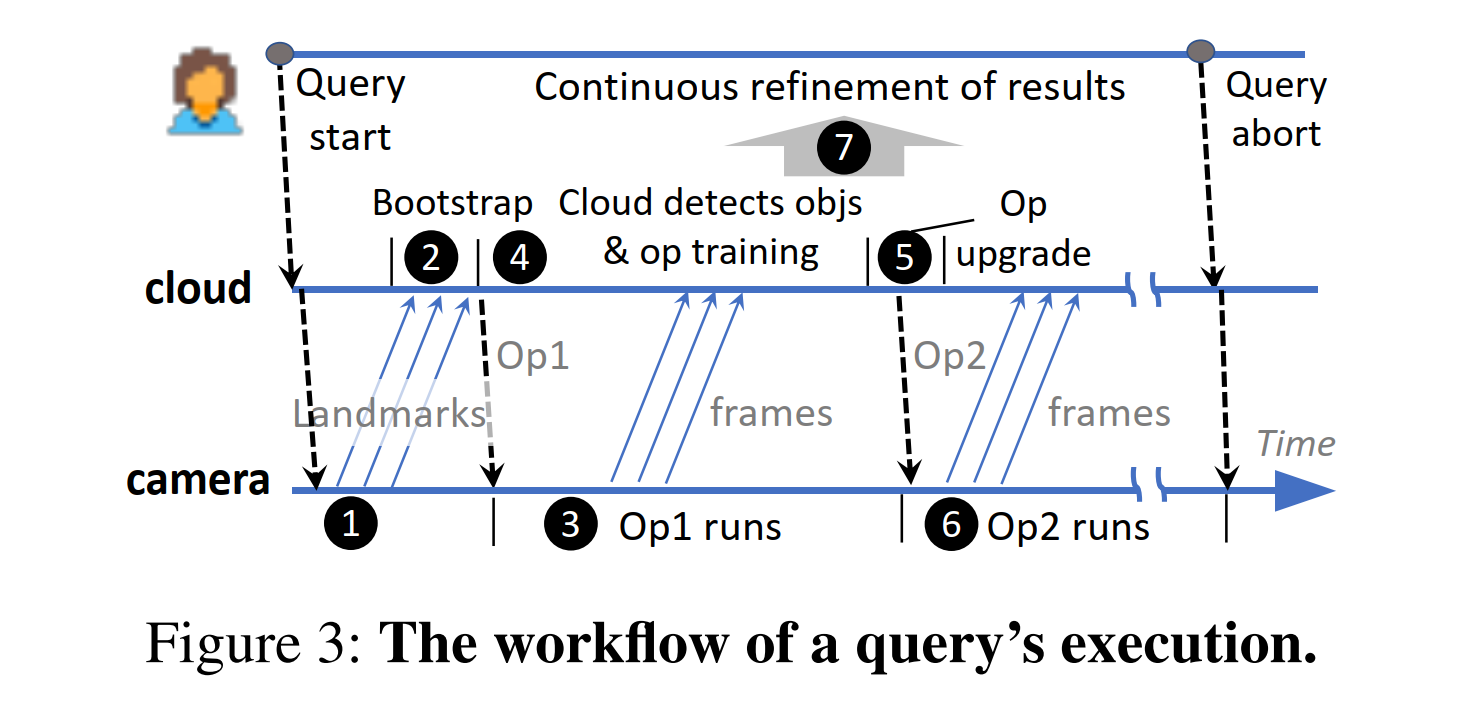
感觉到这里两个idea有点矛盾,第一个idea说摄像头算力有限,第二个idea又开始在摄像头端运行高精度模型。而且低精度模型的结果真的可信吗?false negative和false positive真的可以控制吗?从设计上来说也有局限性,例如对短视频来说流程非常繁琐,landmarks可能信息量不够等。
而且实验用的数据集居然是720P at 1FPS lasting 48 hours,根本不能算是video,可以说实验没有做到文章设想的东西,对比之下junchen jiang组的文章质量要高多了。