16,17年这几篇文章虽然已经很久远了,他们提出的东西已成为现在的共识,但目前还是很多人将他们作为baseline,看这些文章还是有价值。
推荐系统的主要挑战之一是同时解决Memorization和Generalization,Memorization是记住并利用出现过的user-item关系,Generalization是发掘未知的user-item关系,增加推荐多样性。后者可以支持我们的idea。
Memorization用简单的线性模型如logistic regression,对训练集中未出现过的item就无法判断。Generalization用embedding-based models,因为item很多,用户感兴趣的只有一部分,是很稀疏的高秩的,如果将他们映射到低维特征,会导致过度泛化。文章想结合两种方法,提出的模型结构如下:
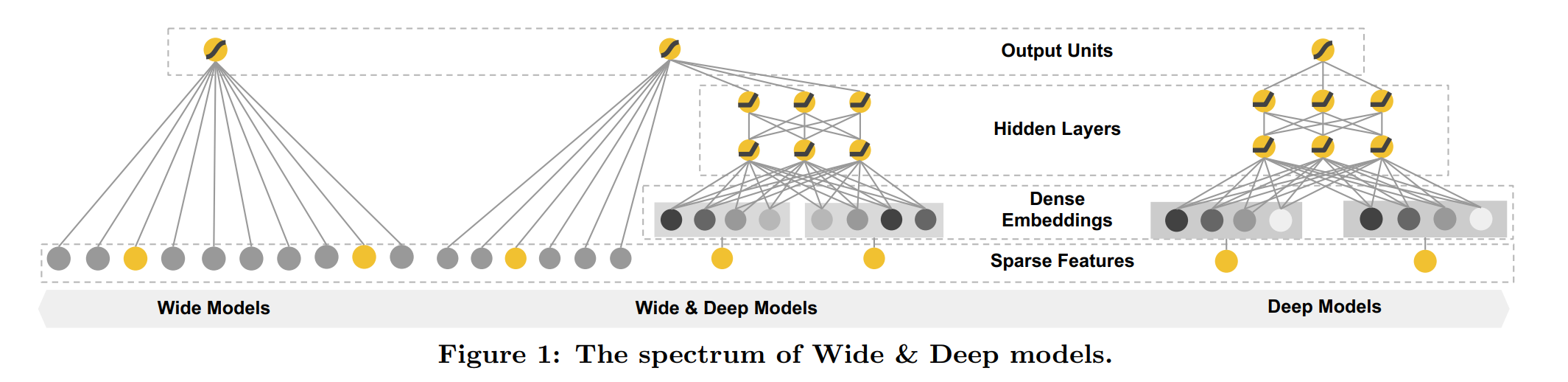
wide部分就是y = w^T x + b,为了给线性模型加上非线性特征Φ(x),还会设计一些cross-product transformation,比如某个特征为1当且仅当其他两个特征都为1。对于一个item x的分类预测如下:
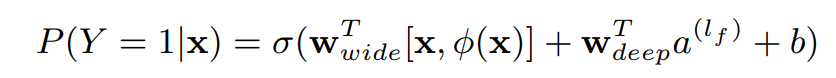
文章在serve的时候是多线程的小batch并行推理,和我们的idea的思想是接近的,但这只是单机的并行推理,batch量并不大。
推荐系统名词解释
impression:用户观察到曝光的产品
click:用户对impression的点击行为
conversion:用户点击之后对物品的购买行为
CTR(Clickthrough rate):从impression到click的比例
CVR:从click到conversion的比例
CTCVR:从impression到conversion的比例